Blog
-

OpenAI Lifeboat by Replicate
Replicate introducing the OpenAI Lifeboat. They made a proxy so you can switch your language model provider to Llama 70B with 3 lines of code. It’s free for the next week. Quick Start To get started, create a Replicate account and copy your API token. Set your token as an environment variable. Install the OpenAI client if you haven’t…
-

LLamaIndex CLI
Create-LLama – a new command-line utility (CLI) for crafting LlamaIndex applications. This sounds like an exciting development for those interested in leveraging large language models (LLMs) like GPT-4 for data interaction and analysis. Here’s a simplified breakdown of the key points from your description: Additional Configurations Customization and Deployment Post-setup, the app can be customized…
-

Llama 2 in DirectML
At this year’s Inspire event, the team from Microsoft discussed the capability for developers to operate Llama 2 on Windows, utilizing DirectML and the ONNX Runtime. Their efforts have been focused on turning this into a tangible reality. Progress is evident with the introduction of a sample showcasing Llama 2 7B, accessible at GitHub –…
-
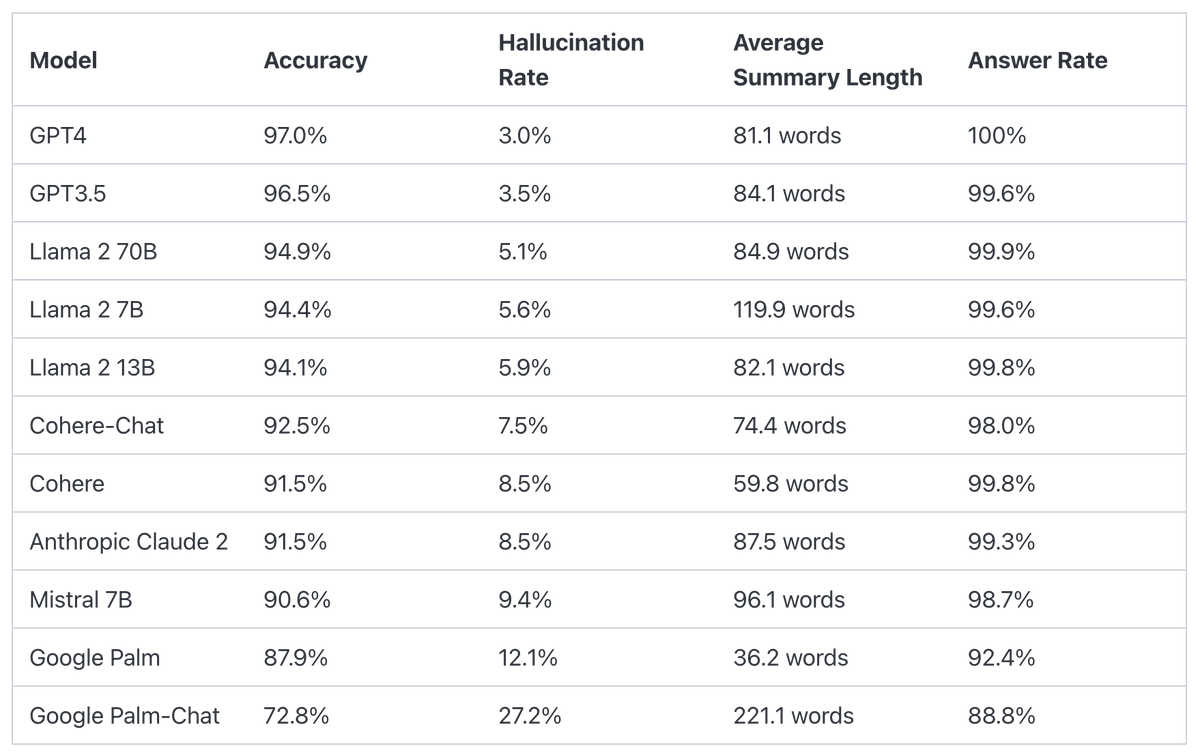
Hallucination Leaderboard (GPT-4, LLama, Claude 2)
Finally, we have a hallucination leaderboard! Key Takeaways: Really cool that we are beginning to do these evaluations and capture them in leaderboards! Hallucination Comparison Table The leaderboard for publicly available language models has been determined through the use of Vectara’s Hallucination Evaluation Model. This tool assesses the frequency with which a language model generates…
-

Llama 2-13B now available on Amazon Bedrock
Meta’s Llama 2 Chat Model (13B) is now available on Amazon Bedrock! Amazon Bedrock has introduced a groundbreaking service as the first public cloud platform to offer a fully managed API for Llama 2, Meta’s advanced LLM. This development allows entities of various sizes to utilize the Llama 2 Chat models through Amazon Bedrock, eliminating…
-

Speed Up Inference on Llama 2
This blog post explores methods for enhancing the inference speeds of the Llama 2 series of models with PyTorch’s built-in enhancements, including direct high-speed kernels, torch compile’s transformation capabilities, and tensor parallelization for distributed computation. We’ve achieved a latency of 29 milliseconds per token for individual requests on the 70B LLaMa model, tested on eight…
-
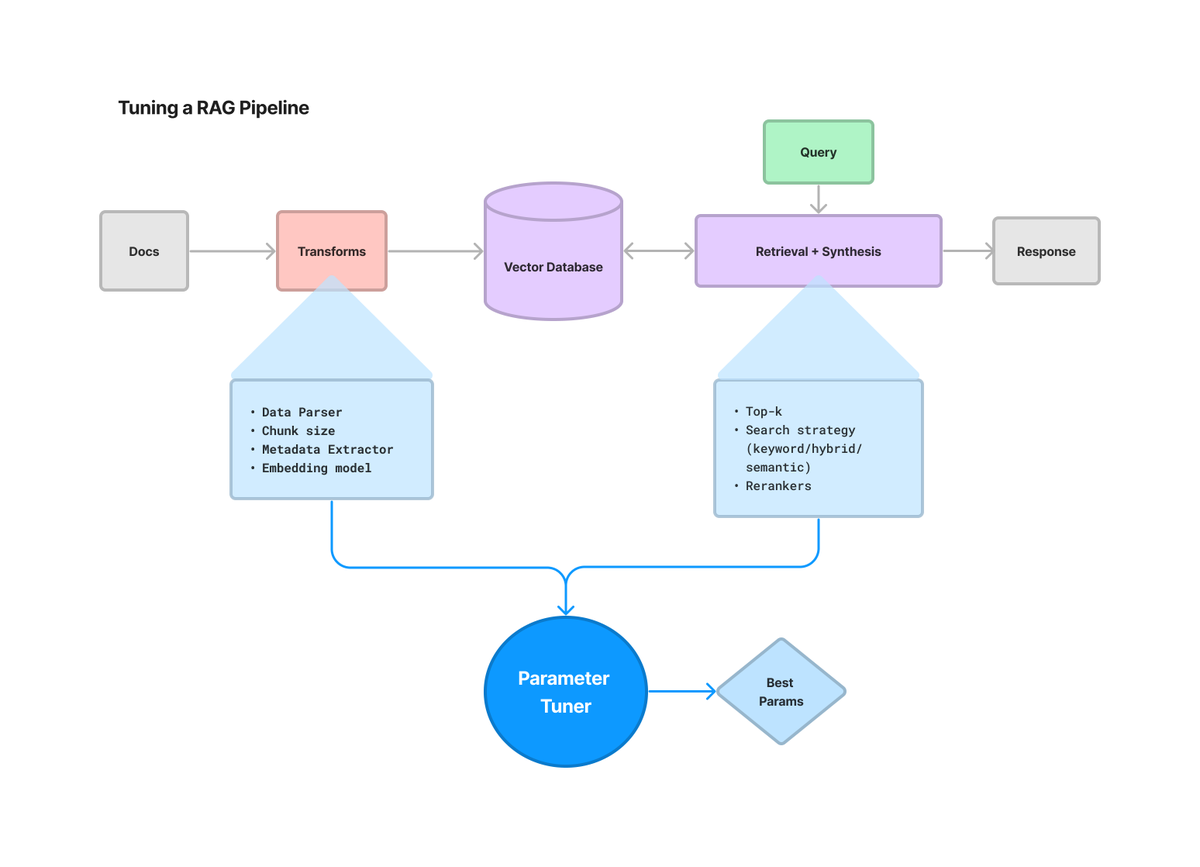
Hyperparameter Tuning for RAG
A HUGE issue with building LLM apps is there’s way too many parameters to tune and it extends way beyond prompts: chunking, retrieval strategy, metadata, just to name a few. LlamaIndex have a full notebook guide showing you how to optimize a sample RAG pipeline w/ 1) chunk size, and 2) top-k. Try it out…
-

Llama 2 for Enterprise
Dell has expanded its hardware offerings with the inclusion of support for the Llama 2 models in its Dell Validated Design for Generative AI and on-site generative AI solutions. Meta introduced Llama 2 in July, garnering support from several cloud services, including Microsoft Azure, AWS, and Google Cloud. However, Dell’s initiative stands out as it…
-

Getting started with Llama-2
This manual offers guidance and tools to assist in setting up Llama, covering access to the model, hosting, instructional guides, and integration methods. It also includes additional resources to support your work with Llama-2. Acquiring the Models Hosting Options Amazon Web Services (AWS) AWS offers various hosting methods for Llama models, such as SageMaker Jumpstart,…