
This manual offers guidance and tools to assist in setting up Llama, covering access to the model, hosting, instructional guides, and integration methods. It also includes additional resources to support your work with Llama-2.
Acquiring the Models
- Go to the Llama-2 download page and agree to the License.
- Upon approval, a signed URL will be sent to your email.
- Clone the Llama 2 repository here.
- Execute the download.sh script and input the provided URL when asked to initiate the download.
- Note: Links expire after 24 hours or a certain number of downloads. If you encounter 403: Forbidden errors, you can re-request a link.
Hosting Options
Amazon Web Services (AWS)
AWS offers various hosting methods for Llama models, such as SageMaker Jumpstart, EC2, and Bedrock. This document focuses on using SageMaker Jumpstart and Bedrock. For other AWS services, visit their website.
Bedrock: A fully managed service providing high-performance foundational models through an API. It simplifies development while ensuring privacy and security. Learn more about Bedrock here and find instructions for using Llama 2 with Bedrock here.
SageMaker JumpStart: Enables ML professionals to build, train, and deploy ML models with fully managed infrastructure. SageMaker JumpStart offers a wide selection of foundational models for deployment. More details here.
Cloudflare
Workers AI: Offers serverless GPU-powered inference on Cloudflare’s global network. It’s an AI inference service enabling developers to run AI models with minimal coding. Discover more about Workers AI here and see the documentation for using Llama 2 models here.
Google Cloud Platform (GCP) – Model Garden
GCP provides cloud computing services and virtual machines. Model Garden on Vertex AI offers infrastructure to start your ML project, with over 100 foundation models available. Learn more about deploying AI models and running fine-tuning tasks in Google Colab n appropriate Google Page.
Vertex AI: In collaboration with Vertex AI, Meta team integrated Llama 2, offering pre-trained, chat, and CodeLlama in various sizes. Start here, noting the need for GPU computing quota.
Hugging Face
Request a download using the same email as your Hugging Face account. Within 1-2 days, you’ll gain access to all versions of the models.
Kaggle
Kaggle is a community for data scientists and ML engineers, offering datasets and trained ML models. We’ve partnered with Kaggle to integrate Llama 2. Request a download using your Kaggle email to access Llama 2 and Code Lama models.
Microsoft Azure & Windows
Azure Virtual Machine: Deploy Llama 2 on an Azure VM. Use Azure’s Data Science VM or set up your own. Instructions for the Data Science VM are here. For your own VM, follow Microsoft’s quickstart here.
Azure Model Catalog: A hub for foundation models, allowing easy running of ML tasks. We’ve integrated Llama 2 with Model Catalog, offering pre-trained chat and CodeLlama models. Start here.
ONNX for Windows
ONNX is an open format for ML models, compatible with various frameworks. Using ONNX runtime accelerates development and enables running ML tasks on platforms like Windows. Begin developing for Windows/PC with the official ONNX Llama 2 repo here and ONNX runtime here. Note: Request model artifacts from sub-repos for access.
If your goal is to enhance your skills through coding, it’s strongly advised to explore the “Getting to Know Llama 2 – Jupyter Notebook.” This resource serves as an excellent starting point, offering insights into the most frequently executed operations on Large Language Models (LLMs).
Fine Tuning Llama-2
Full parameter fine-tuning involves adjusting all the parameters across all layers of a pre-trained model. While this method often yields the best results, it’s also the most demanding in terms of resources and time, requiring substantial GPU power and taking the longest to complete.
PEFT, or Parameter Efficient Fine Tuning, offers a way to fine-tune models with minimal resources and costs. Two notable PEFT methods are LoRA (Low Rank Adaptation) and QLoRA (Quantized LoRA). These methods involve loading pre-trained models onto the GPU with quantized weights—8-bit for LoRA and 4-bit for QLoRA. It’s feasible to fine-tune the Llama 2-13B model using LoRA or QLoRA with just a single consumer GPU with 24GB of memory. Notably, QLoRA demands even less GPU memory and reduces fine-tuning time compared to LoRA.
Typically, it’s advisable to start with LoRA, or QLoRA if resources are particularly constrained, and then assess the performance post fine-tuning. Full fine-tuning should only be considered if the results from PEFT methods don’t meet the desired standards.
Prompting Llama 2
Prompt engineering is a method employed in natural language processing (NLP) to enhance the performance of language models. This technique involves crafting prompts—concise text snippets that supply extra context or instructions to the model, such as the subject or style of the text it’s expected to generate.
Through these prompts, the model gains a clearer understanding of the desired output, leading to more precise and pertinent results. In the case of Llama 2, the context size, measured in the number of tokens, has expanded significantly, doubling from 2048 to 4096 tokens. This increase allows for more extensive context and potentially richer interactions with the model.
Crafting Effective Prompts
Crafting effective prompts is a crucial aspect of prompt engineering. Here are some strategies for creating prompts that can enhance the performance of your language model:
- Clarity and Conciseness: Ensure your prompt is straightforward and provides sufficient information for the model to generate relevant responses. Steer clear of jargon or complex terms that might confuse the model.
- Incorporate Specific Examples: Including detailed examples in your prompt can guide the model more effectively. For instance, if you want the model to create a story, include elements about the setting, characters, and plot.
- Diversify Your Prompts: Experimenting with various prompts can aid the model in understanding the task better and yield more varied and imaginative outputs. Experiment with different styles, tones, and structures.
- Test and Refine: After developing your prompts, test them with the model. If the outcomes aren’t as anticipated, refine your prompts by adding more specifics or altering the tone and style.
- Leverage Feedback: Utilize feedback from users or other sources to continuously refine your prompts. This can help pinpoint areas where the model requires more direction and enable you to make necessary adjustments.
Code Llama
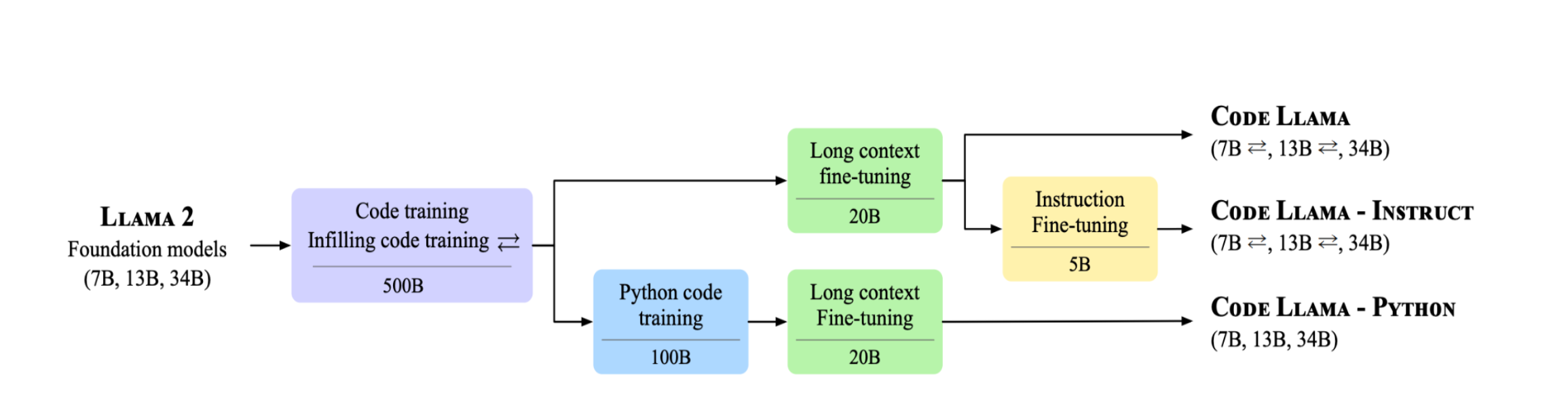
Code Llama is an open-source collection of Large Language Models (LLMs) built upon Llama 2, delivering state-of-the-art (SOTA) performance for coding-related tasks. This family comprises:
- Foundation Models (Code Llama): These are the core models in the Code Llama series, designed to handle a wide range of coding tasks.
- Python Specializations (Code Llama – Python): These models are specifically fine-tuned for Python programming, offering enhanced performance for Python-related coding tasks.
- Instruction-Following Models (Code Llama – Instruct): These models are tailored to follow instructions more effectively, making them suitable for tasks that require understanding and executing specific directives.
Code LLama Model sizes
Each of these models comes in three sizes, with 7B, 13B, and 34B parameters, catering to different levels of complexity and computational requirements.
If the Code Llama models (7B/13B/34B) are not yielding satisfactory results for a specific task, such as converting text to SQL, fine-tuning the model may be necessary. Here’s a comprehensive guide and notebook on how to fine-tune Code Llama using the 7B model hosted on Hugging Face:
- Fine-Tuning Method: The guide employs the LoRA (Low Rank Adaptation) fine-tuning method, which is resource-efficient and can be executed on a single GPU.
- Code Llama References: As indicated in the Code Llama References (link here), fine-tuning has been shown to enhance Code Llama’s capabilities in generating SQL code. This improvement is crucial since Large Language Models (LLMs) need to effectively interact with structured data, with SQL being the primary means of accessing such data.
- Demonstration Applications: To illustrate the enhanced capabilities post fine-tuning, demo applications are being developed using LangChain and RAG with Llama 2. These applications will showcase how the fine-tuned models can effectively work with structured data and SQL.
This guide and notebook provide a step-by-step process for fine-tuning, making it accessible even for those with limited experience in this area. Fine-tuning can significantly boost the model’s performance on specialized tasks, making it a valuable tool for developers and researchers working with Code Llama.
LangChain
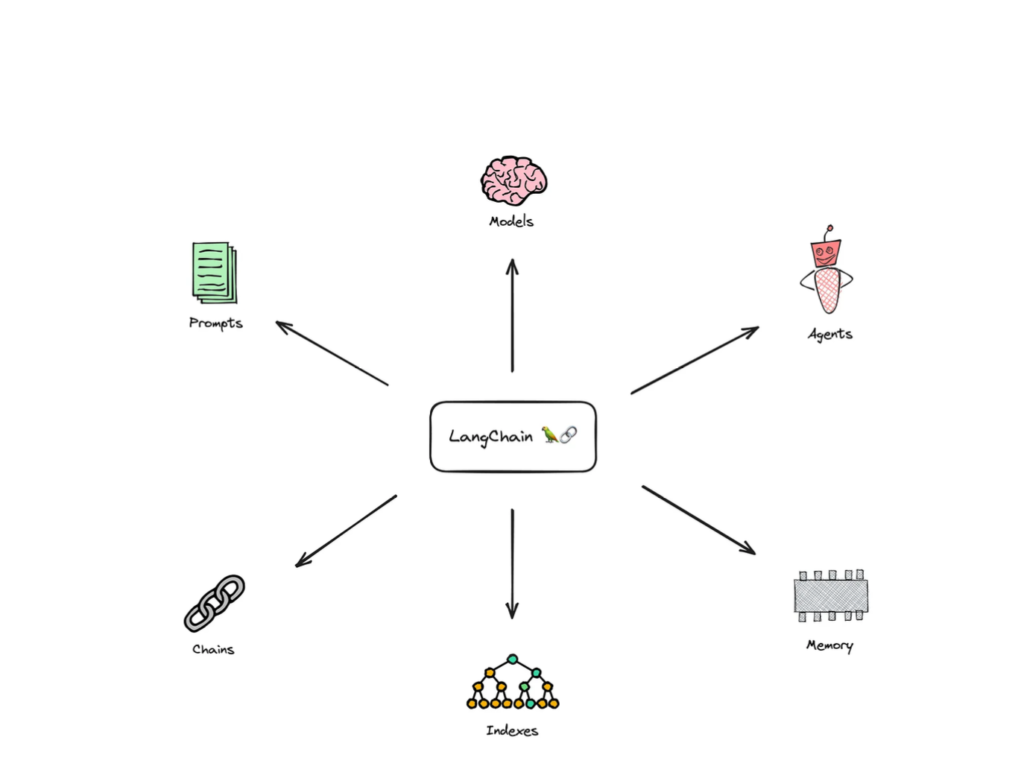
LangChain is indeed an open-source framework designed to facilitate the creation of applications powered by Large Language Models (LLMs). Moreover, it provides a set of common abstractions and higher-level APIs, streamlining the app development process by eliminating the need to interact with LLMs from scratch. The main building blocks or APIs of LangChain include:
- Chains: These are sequences of components that process input and generate output. Chains allow for the modular construction of application workflows.
- Components: These are individual units within a chain that perform specific tasks. Components can range from language models to data retrieval systems.
- Interactors: These handle the interaction between the user and the system, managing input and output.
- Retrievers: These are responsible for fetching information from external sources, which can then be used by the language model for generating responses.
- Generators: These components are typically language models that generate text based on the input and context provided.
- Combiners: These are used to merge or combine outputs from different components or sources.
- Context Managers: These manage the context or state of a conversation or interaction, ensuring continuity and relevance in responses.
- Evaluators: These components assess the quality or relevance of the generated output, ensuring that the responses meet certain criteria or standards.
Moreover, by utilizing these building blocks, LangChain allows developers to construct sophisticated LLM-powered applications with greater ease and efficiency, focusing on the unique aspects of their application rather than the underlying complexities of working directly with LLMs.
LangChain APIs
The LLMs API facilitates seamless integration with leading Large Language Models (LLMs) like Hugging Face and Replicate, hosting a variety of Llama 2 models.
In addition, the Prompts API offers a valuable prompt template feature, enabling easy reuse of effective, often intricate, prompts for advanced LLM application development. It includes numerous built-in prompts for common tasks such as summarization or SQL database integration, accelerating app creation. Additionally, prompts can be paired with parsers for efficient extraction of pertinent information from LLM responses.
The Memory API is designed to store conversational history and incorporate it with new inquiries when interacting with LLMs, supporting multi-turn, natural dialogues.
The Chains API encompasses the fundamental LLMChain, which merges an LLM with a prompt to produce output, and extends to more complex chains for systematic development of intricate LLM applications. For instance, the output from one LLM chain can serve as the input for another, or a chain might handle multiple inputs and/or outputs, either predetermined or dynamically determined based on the LLM’s response to a prompt.
Besides, the Indexes API enables the storage of external documents in a vector store after converting them into embeddings, which are numerical representations of the documents’ meanings. When a user poses a question about these documents, the pertinent data from the vector store is retrieved and combined with the query, allowing the LLM to generate a response related to the documents. The process is outlined as follows:
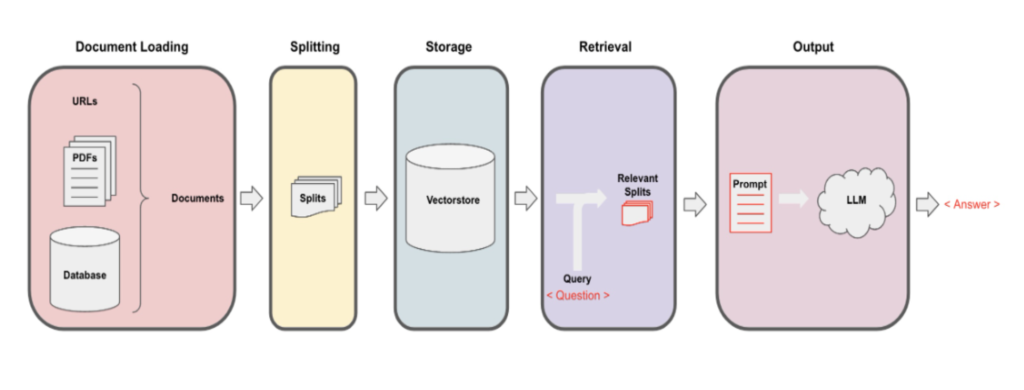
LangChain serves as an effective retrieval augmented generation (RAG) tool, enabling the integration of internal or recent public data with LLMs for question-answering or conversational purposes. It is already equipped to handle various forms of unstructured and structured data.
For further insight into LangChain, consider enrolling in the two complimentary LangChain short courses available at deeplearning.ai’s short courses. Please note that the course material utilizes the OpenAI ChatGPT LLM, but demonstrations of LangChain applications with Llama 2 will be released soon.
LlamaIndex
LlamaIndex is a widely recognized open-source framework for creating LLM applications. Similar to LangChain, it facilitates the development of retrieval augmented generation (RAG) applications by seamlessly integrating external data with LLMs. LlamaIndex offers three essential tools:
- Connecting Data: It allows the connection of any data type—structured, unstructured, or semi-structured—to LLMs.
- Indexing Data: This feature enables the indexing and storage of data.
- Querying LLM: LlamaIndex combines user queries with retrieved data relevant to the query, enabling the LLM to provide data-augmented answers.
LlamaIndex primarily focuses on being a data framework that links private or domain-specific data with LLMs, excelling in intelligent data storage and retrieval. On the other hand, LangChain is a more versatile framework designed for building agents that connect multiple tools. However, it’s possible to use LangChain in conjunction with LlamaIndex.
Both frameworks, which have now evolved into venture capital-backed startups, are undergoing rapid development. This means they are continually adding new or improved features to address their limitations. For instance, LlamaIndex recently introduced data agents, while LangChain has expanded its support for numerous data loaders.
We’re excited to announce that we’ll soon be releasing open-source demo applications that utilize both LangChain and LlamaIndex, showcasing their capabilities with Llama 2.
Resources
Github
- Llama 2 Repository : Main Llama 2 repository
- Llama 2 Recipes : Examples and fine tuning
- Code Llama Repository : Main Code Llama repository
- Getting to know Llama 2 – Jupyter Notebook
- Code Llama Recipes : Examples
Performance & Latency
- Hamel’s Blog – Optimizing and testing latency for LLMs
- vLLM – How continuous batching enables 23x throughput in LLM inference while reducing p50 latency
- Paper – Improving performance of compressed LLMs with prompt engineering
- Llama2 vs GPT 4 Cost comparison for text summarization
Fine Tuning
- Hugging Face PEFT
- Llama Recipes Fine Tuning
- Fine Tuning Data Sets
- GPT 3.5 vs Llama 2 fine-tuning
- https://deci.ai/blog/fine-tune-llama-2-with-lora-for-question-answering/
Code Llama
- https://www.snowflake.com/blog/meta-code-llama-testing/
- https://www.phind.com/blog/code-llama-beats-gpt4
Others