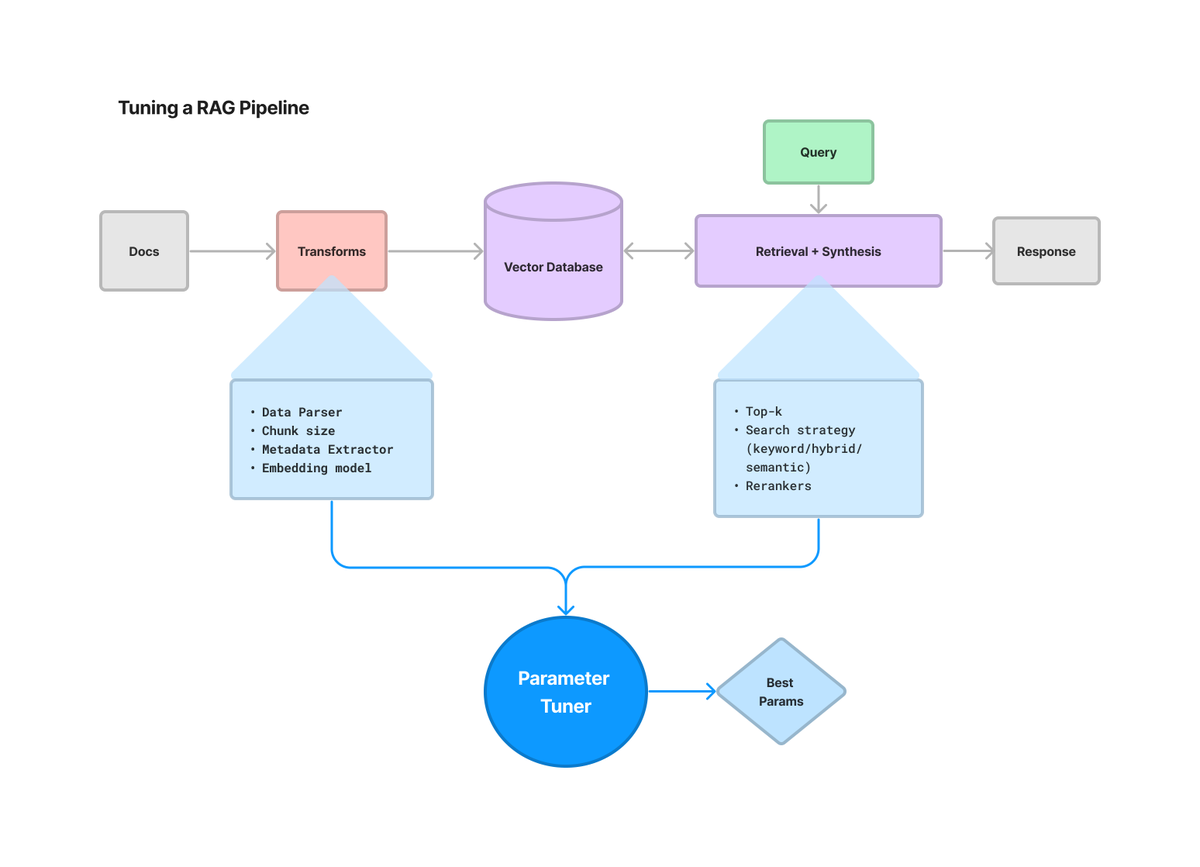
A HUGE issue with building LLM apps is there’s way too many parameters to tune and it extends way beyond prompts: chunking, retrieval strategy, metadata, just to name a few.
- You can now do this automatically/efficiently, with our new
ParamTunerabstractions. - Define any objective function you want (e.g. RAG pipeline with evals),
- Grid search in a sync or async fashion,
- ake it to the next level with Ray Tune.
LlamaIndex have a full notebook guide showing you how to optimize a sample RAG pipeline w/ 1) chunk size, and 2) top-k.
- Setup: load source docs (llama2), define golden dataset,
- Objective function: define RAG pipeline over data, run evals over dataset and output score,
- Select the best top-k / chunk size.
Try it out and let us know what you think!
Caveats:
⚠️ This is experimental, the abstractions may be refined.
⚠️ By default does a big grid-search. Beware of costs 💵.
See the full Guide.
Read other articles: