Want to build ChatGPT for your own data? LLaMa 2 + RAG (Retrieval Augmented Generation) is all you need! But what exactly is RAG?
- Retrieve relevant documents from an external knowledge base.
- Augment the retrieved documents with the original prompt.
- Generate output text using a large language model.
Within a chatbot framework, RAG empowers LLMs like Llama 2 to produce responses that are grounded in contextual relevance.
When a user poses a question or a statement, the system consults the document store, identifies the appropriate context, and crafts a response based on that knowledge.
How to build RAG apps with LLMs?
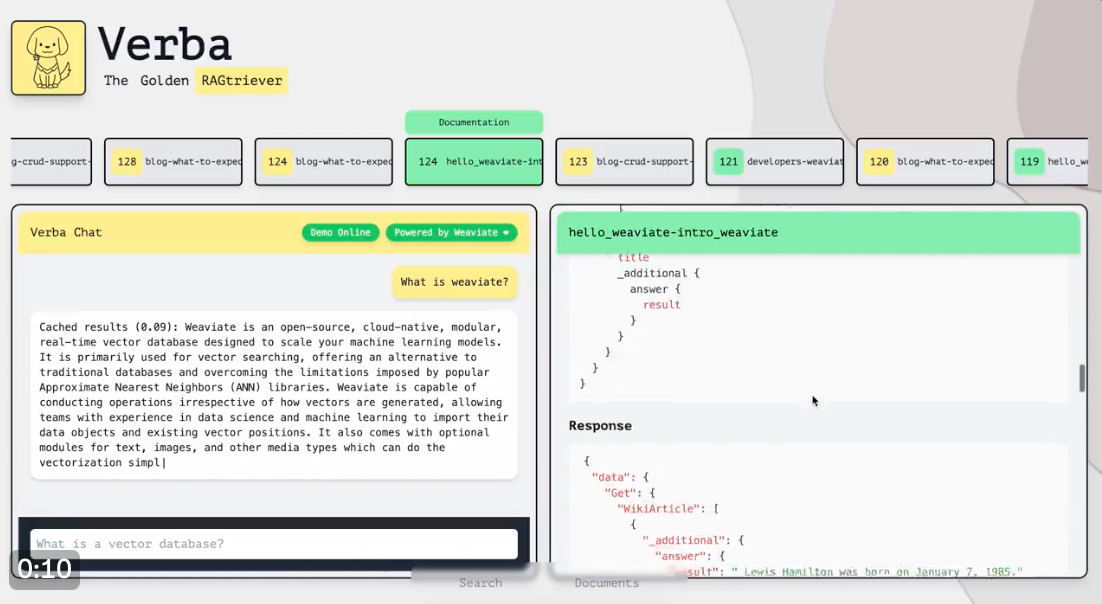
Meet Verba, the opensource user interface for building RAG applications. It combines weaviates vector database with LLMs to provide next level of conversational abilites to your chatbot.
Verba fetches context from your documents to provide in-depth answers. It uses LLMs to ensure the information you get is not only accurate but contextually spot-on, all through a user-friendly interface.
Why should you care?
- Effortless Data Import: Verba supports a variety of file types, making your data integration effortless. It chunks and vectorizes your info to set it up for swift search and retrieval.
- Accelerate Queries with Semantic Cache: Verba uses Semantic Cache to embed your results and queries, ensuring that your next search is faster than ever.
- Advanced Search: Integration with Weaviate’s generate module that sift through your documents to identify contextually relevant fragments used by an LLM to formulate comprehensive answers to your queries.
Read related articles: