
This blog post explores methods for enhancing the inference speeds of the Llama 2 series of models with PyTorch’s built-in enhancements, including direct high-speed kernels, torch compile’s transformation capabilities, and tensor parallelization for distributed computation. We’ve achieved a latency of 29 milliseconds per token for individual requests on the 70B LLaMa model, tested on eight A100 GPUs. We’re eager to share these insights with our peers and have provided our code for community use.
INTRODUCTION
The current landscape of generative AI is witnessing a surge in the availability of mammoth language models, with parameter counts in the tens of billions. While the proliferation of such models is undeniable, a significant challenge persists in deploying them cost-effectively. The AI community has experimented with numerous strategies to varying successes and compromises. Hardware-centric optimizations like NVIDIA’s Faster Transformer are limited to particular hardware, whereas more generalized methods such as ONNX trade off efficiency for flexibility.
Last year’s launch of PyTorch compile marked the beginning of an IBM and PyTorch collaboration to refine model compilation for better inference performance, aiming to cut down latency for each token generated by these large models.
SELECTION OF MODELS
Our benchmarks focus on the widely-used Llama 2 model family. The specific models of interest for this discussion, along with their relevant hyperparameters, are detailed in the following table:
| Model size | Hidden dimension | Num heads | Num layers | Attention type |
| 7B | 4096 | 32 | 32 | MHA |
| 13B | 5120 | 40 | 40 | MHA |
| 70B | 8192 | 64 | 80 | GQA |
The models we’re discussing are decoder-only, which means they generate tokens one after the other, typically accelerated by key-value (KV) caching. We adopt this technique for our latency and throughput benchmarks.
INFERENCE METHODOLOGY
Our inference objective is to swiftly achieve optimal latencies, keeping pace with the rapid evolution of new model architectures within the AI field. A native PyTorch solution is desirable because it allows for the broadest model compatibility. We identify four distinct methods that accelerate inference:
- (a) kernel fusion with compile,
- (b) use of faster kernels,
- (c) tensor parallelism for large-scale models, and
- (d) model quantization.
For our purposes, we leverage the first three – employing PyTorch compile in conjunction with SDPA’s accelerated kernels and a bespoke tensor parallel framework to realize inference latencies of 29 milliseconds per token on the 70B LLaMa model, as gauged across eight NVIDIA A100 GPUs catering to a single user.
Full Throttle with Compile!
PyTorch Compile enhances performance by reducing CPU overhead through tracing and capturing execution graphs, ideally consolidating the process into a single CPU-to-GPU graph execution. However, compile can introduce ‘graph breaks’ when facing model architectures or operations it doesn’t support. For instance, complex operations such as einops currently evade compile’s capabilities. Likewise, tensor parallelism can cause graph breaks at each layer if the tensor parallel framework doesn’t use traceable communication collectives. Without addressing these graph breaks, the compiled artifacts may underperform or even be slower than regular eager execution. To harness the full potential of compilation, these breaks must be resolved.
Here’s how we addressed these challenges for the 70B LLaMa 2 model to fully utilize compile.
Initially, when we attempted to compile the stock Llama 2 model using torch.compile, it failed due to unsupported complex operations. Turning on TORCH_COMPILE_DEBUG = 1, we found that the RoPE positional encodings were using complex number functions, leading to graph breaks and considerable deceleration. To mitigate this, we restructured the RoPE function to avoid torch.einsum (which originally used torch.polar, also incompatible with compile), opting instead for torch.cos and torch.sin functions.
self.cached_freqs[dev_idx][alpha] = torch.stack(
[
torch.cos(freqs),
-torch.sin(freqs),
torch.sin(freqs),
torch.cos(freqs),
],
dim=2,
).view(*freqs.shape, 2, 2)Our implementation of the frequencies computation
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
t = t / self.scaling_factor
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(dtype), persistent=False)
self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(dtype), persistent=False)Hugging Face implementation of the frequencies computation.
After addressing the RoPE issue, we successfully compiled the 7B and 13B models without encountering any graph breaks on a single A100 GPU.
For the efficient computation of attention mechanisms, we employed SDPA, which is PyTorch’s native implementation that supports tracing (necessary for compilation). To circumvent potential graph breaks that arise when forcing a single algorithm choice through a Python context – the standard recommendation – we resorted to utilizing the torch.backends.cuda.enable_*_sdp functions.
attn = torch.nn.functional.scaled_dot_product_attention(
queries,
keys_e,
values_e,
attn_mask=attn_mask,
dropout_p=self.p_dropout if self.training else 0.0,
is_causal=is_causal_mask,
)Attention computation using SDPA
For attention computation, SDPA was utilized effectively on smaller models, but when we scaled up to the 70B model, we encountered limitations due to the GPU memory constraints. Even using half-precision floats, the 70B model was too large for a single GPU, necessitating the use of tensor parallelism for inference. When attempting to compile the 70B model with torch.compile, we faced 162 graph breaks because of two all-reduce operations per layer, and one all-gather operation each for forward and reverse embeddings. This resulted in no noticeable decrease in inference latency.
At the time of writing, PyTorch’s distributed tensor parallelism did not integrate with torch.compile, which led us to develop our own tensor parallelism code from the ground up. This new code relied exclusively on traceable collective operations to be compatible with torch.compile. With this revision, the PyTorch compiler no longer introduced graph breaks, and we observed a substantial improvement in inference speed. In concrete terms, we achieved an inference latency of 29 milliseconds per token with the 70B Llama model using eight A100 GPUs, marking a 2.4-fold enhancement compared to the baseline, unoptimized inference performance.
Serving aspects
The final aspect to consider is that merely compiling a model using torch.compile is not enough for serving it in a live production environment. To achieve the mentioned performance levels along with high throughput, it is necessary to implement dynamic batching and support for nested tensors. Furthermore, a warm-up phase is crucial to pre-compile the model for different sequence lengths, which are categorized into buckets. These efforts are ongoing to ensure such performance levels are feasible in a production context.
EXPERIMENTS AND MEASUREMENTS
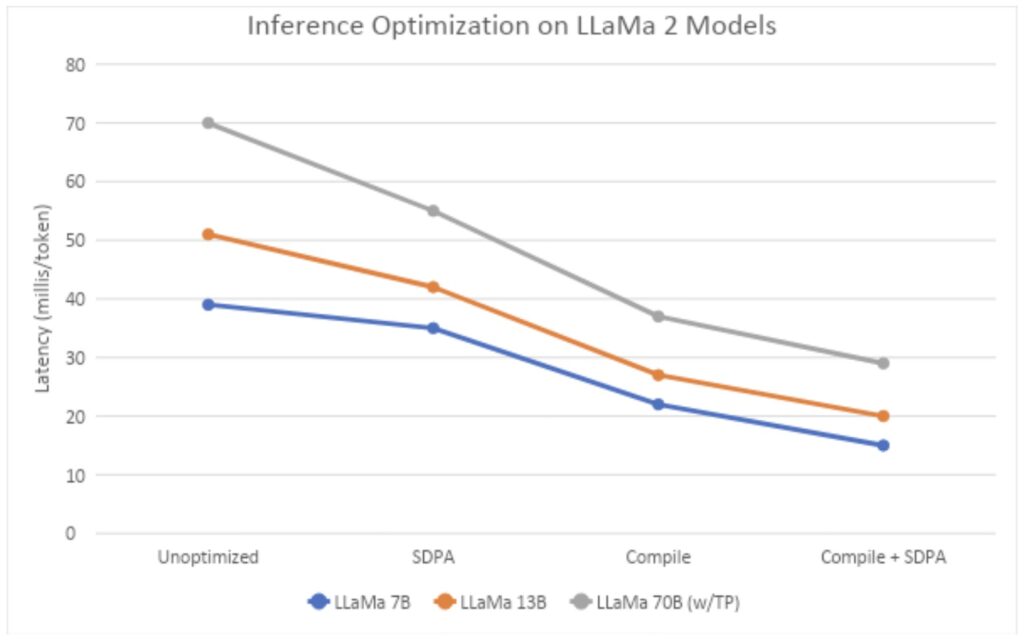
In our experimental setups and measurements, we utilized nodes equipped with 8 A100 NVIDIA GPUs with 80GB each, performing tests in two separate cloud environments (IBM Cloud and AWS, both using OpenShift). We evaluated several different techniques: eager mode, SDPA Flash kernel, Compile, and a combination of Compile and SDPA.
For the 70B model, we employed tensor parallel mode in conjunction with compile and SDPA. The input for this experiment was fixed at 512 tokens with an additional 50 tokens generated. The 7B and 13B models were tested using a single A100 GPU to measure latencies, while the 70B model was tested using 8 A100 GPUs. Specifically for the 70B model, we also utilized the reduce-overhead option available in PyTorch compile that incorporates CudaGraphs to minimize the overhead of CPU to GPU kernel launches.
Interestingly, employing CudaGraphs for the 7B and 13B models did not yield any benefits, hence those results are not included in our report. The findings, as depicted in Figure 1, show that the combination of compile and SDPA achieves remarkably low latencies, with the 70B Llama 2 model recording a latency of 29ms per token.
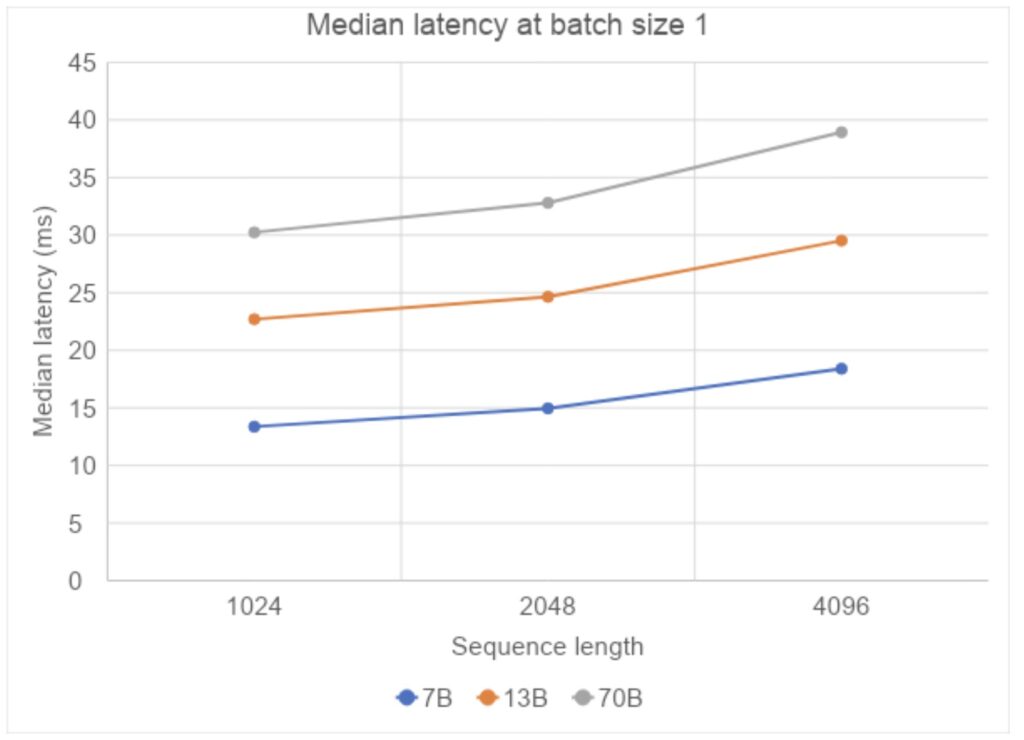
Upon further investigation, we assess the influence of varying sequence lengths on performance, specifically by expanding the sequence length from 1024 to 4096 tokens. The results indicate a sub-linear growth in the median latency per token. This finding is significant as it suggests that the model scales efficiently with larger context sizes.
Thus, when the model processes extensive documents, the increase in response time is not proportional to the increase in document size, ensuring that response times remain within a reasonable range even as the amount of processed data grows.
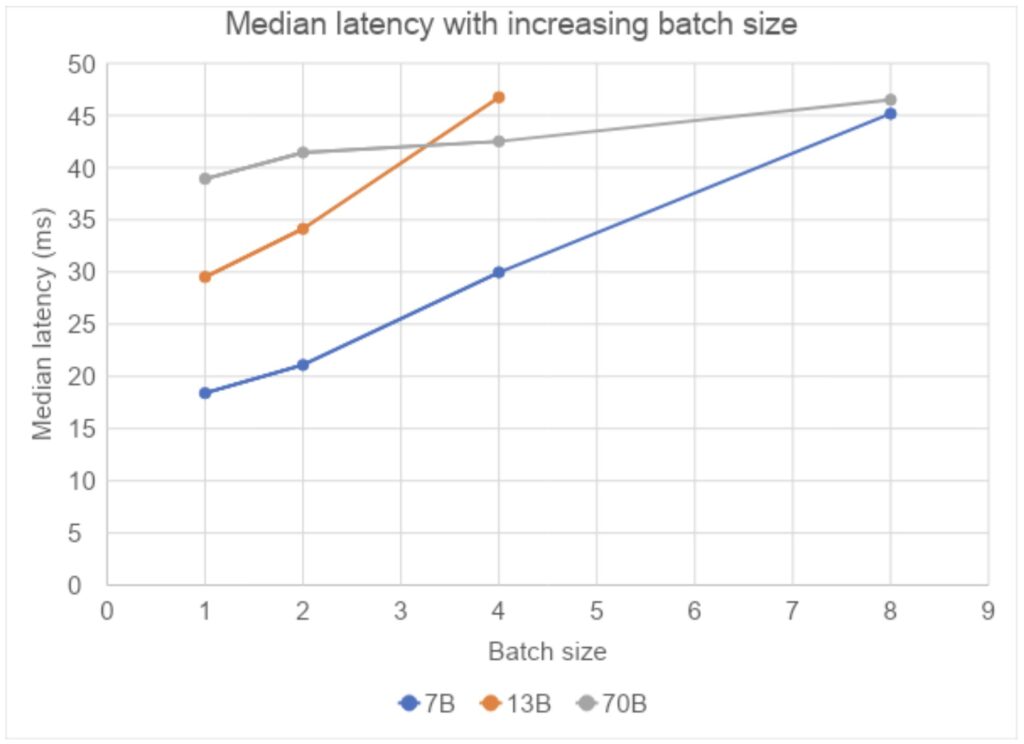
Final Part of Analysis
In the final part of our analysis, we focus on the relationship between batch sizes and response latencies. The data reveals that as batch sizes escalate, the resulting latencies also rise, but in a sub-linear fashion. This means that the latency does not grow as quickly as the batch size, indicating that the system is managing increased loads efficiently.
However, it’s noted that when testing the 13B model at a batch size of 8, an out-of-memory (OOM) error occurs, suggesting the limit of what a single GPU can handle for this model size has been reached. In contrast, for the 70B model, which operates across 8 GPUs with tensor parallelism, we do not encounter OOM issues. This underscores the advantage of distributed computing and tensor parallelism in managing larger models and batch sizes without running into memory constraints.
FINAL THOUGHTS
In concluding remarks, the effectiveness of PyTorch’s compile pathway in achieving remarkably low inference latencies for the 70B model has been established. The forthcoming steps include the incorporation of dynamic batching and nested tensors to leverage the aforementioned optimizations further.
Gratitude is extended to Edward Yang, Elias Ellison, Driss Guessous, Will Feng, Will Constable, Horace He, Less Wright, and Andrew Gu from Team PyTorch. Their diligent code reviews and contributions were instrumental in achieving the reported low latencies using a PyTorch-native methodology. Additional commendations go to the extended Team PyTorch, who have been dedicated to the continual enhancement of PyTorch. Particular acknowledgments are given to the SDPA team for their work on tracing and enabling compile on rapid kernels, as well as the compile team for their guidance in navigating and resolving issues, which includes identifying and reporting bugs in NVIDIA’s CUDA graphs to the driver team.
By IBM Research.
Read other articles: