Meta introduced the Llama 2 series of large language models with sizes varying from 7 billion to 70 billion parameters. Engineers designed these LLMs specifically for dialogue applications. In terms of performance, Llama-2-Chat excels over open-source chat models in many of the benchmarks we assessed. When gauged for helpfulness and safety in human reviews, they match well-known proprietary models such as ChatGPT and PaLM.
Llama 2 models are available in three parameter sizes: 7B, 13B, and 70B, and come in both pretrained and fine-tuned forms. These models solely accept text as input and produce text as output.
The underlying framework for Llama 2 is an auto-regressive language model. Enhanced versions undergo supervised fine-tuning (SFT) and harness reinforcement learning combined with human insights (RLHF) to better resonate with human desires for safety and utility.
| Model | Training Data | Params | Content Length | GQA | Tokens | LR |
| Llama 2 | A new mix of publicly available online data | 7B | 4k | ✗ | 2.0T | 3.0 x 10-4 |
| Llama 2 | A new mix of publicly available online data | 13B | 4k | ✗ | 2.0T | 3.0 x 10-4 |
| Llama 2 | A new mix of publicly available online data | 70B | 4k | ✔ | 2.0T | 1.5 x 10-4 |
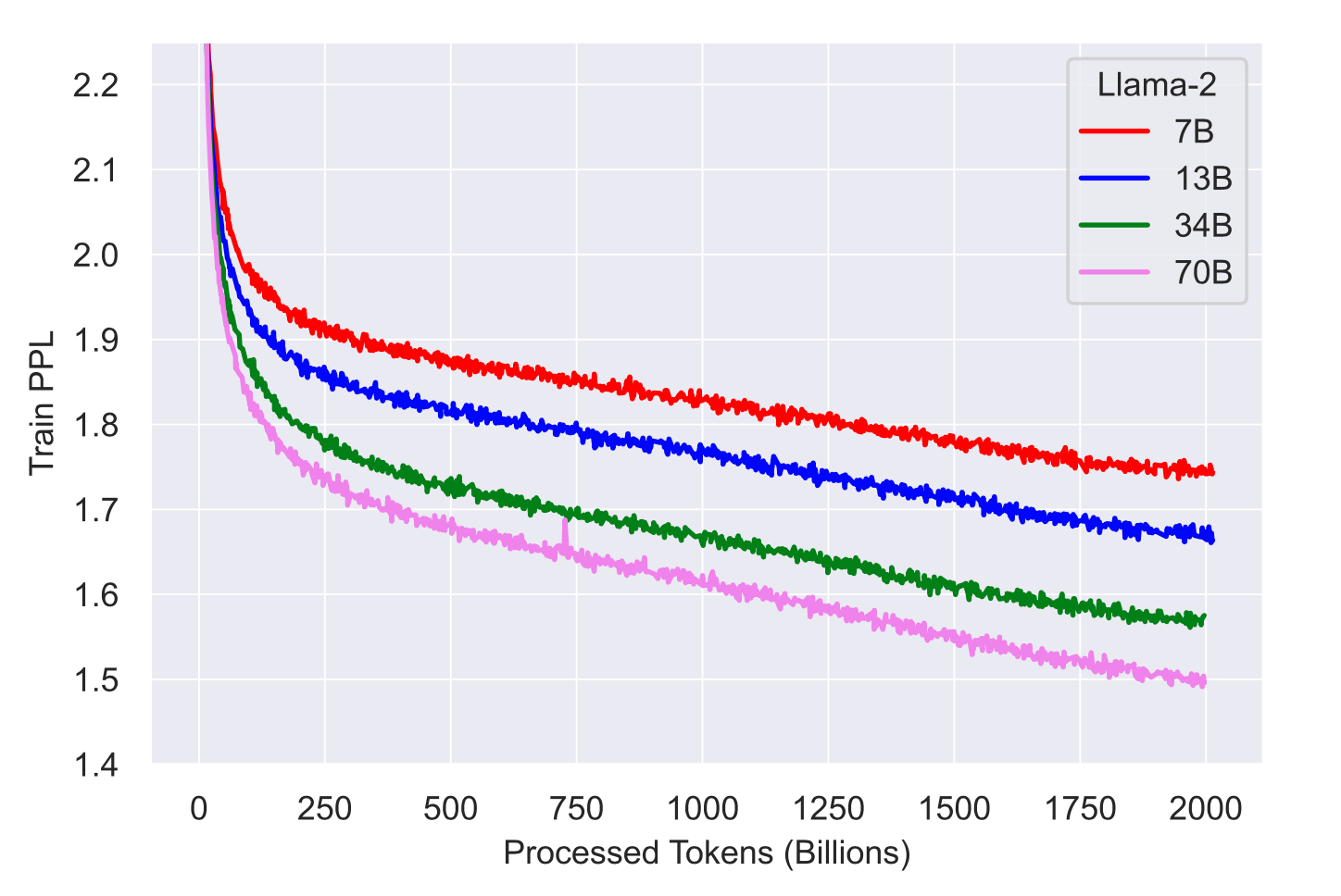
The Llama 2 series of models utilize token counts exclusively from their pretraining data. All models in this series have been trained using a global batch-size encompassing 4M tokens. The 70B iteration employs Grouped-Query Attention (GQA) to enhance inference scalability.
Timeline
Llama 2 underwent training from January to July 2023.
Current Version
This iteration is a static model based on an offline dataset. As Meta further enhance the model’s safety through community insights, subsequent refined versions will be launched.
Licensing
Those interested in a bespoke commercial license can visit: https://ai.meta.com/resources/models-and-libraries/llama-downloads/
Detailed Insights
For an in-depth understanding, refer to the research article titled “Llama-2: Open Foundation and Fine-tuned Chat Models” available here.
Feedback & Queries
Directions on offering feedback or raising queries about the model are available in the model’s README documentation.
Intended Use
Purpose
Llama 2 good for both commercial and academic purposes, specifically targeting English language applications. While tuned models are crafted to function as chat assistants, the pretrained versions are versatile enough for an array of natural language generation tasks.
Limitations
- Activities that breach legal and regulatory standards, including international trade laws, are discouraged.
- Applications in languages other than English.
- Any applications which contradict the terms outlined in the Acceptable Use Policy and Licensing Agreement for Llama 2 are considered inappropriate.
Hardware and Software Information
Training Details
For training the Llama 2 model, we leveraged proprietary training libraries and tapped into the immense computing power of Meta’s Research Super Cluster as well as other production clusters. The stages of fine-tuning, annotating, and evaluating the model were executed on third-party cloud computing platforms.
Environmental Impact
The pretraining phase required an extensive 3.3M GPU hours on A100-80GB hardware, with a Thermal Design Power (TDP) rating between 350-400W. This resulted in a carbon footprint of approximately 539 tCO2eq. In alignment with our commitment to sustainability, Meta offset the entire carbon emissions arising from this process.
| Model | Time (GPU hours) | Power Consumption (W) | Carbon Emitted(tCO2eq) |
|---|---|---|---|
| Llama 2 7B | 184320 | 400 | 31.22 |
| Llama 2 13B | 368640 | 400 | 62.44 |
| Llama 2 70B | 1720320 | 400 | 291.42 |
| Total | 3311616 | 539.00 |
Training Data
Summary
Llama 2 underwent a pretraining process using 2 trillion tokens derived from publicly accessible sources. The data used for fine-tuning comprises standard public instruction datasets, complemented by over a million freshly annotated human examples. It is essential to note that data from Meta users is absent from both the pretraining and fine-tuning datasets.
Recency of Data
While the pretraining dataset stops at September 2022, the fine-tuning dataset extends to incorporate more recent data, up until July 2023.
Evaluation Results
In this segment, a comparative analysis of Llama 1 and Llama 2 models will be presented based on customary academic benchmarks. All these evaluations will utilize our proprietary internal evaluation toolset.
| Model | Size | Code | Commonsense Reasoning | World Knowledge | Reading Comprehension | Math | MMLU | BBH | AGI Eval |
|---|---|---|---|---|---|---|---|---|---|
| Llama 1 | 7B | 14.1 | 60.8 | 46.2 | 58.5 | 6.95 | 35.1 | 30.3 | 23.9 |
| Llama 1 | 13B | 18.9 | 66.1 | 52.6 | 62.3 | 10.9 | 46.9 | 37.0 | 33.9 |
| Llama 1 | 33B | 26.0 | 70.0 | 58.4 | 67.6 | 21.4 | 57.8 | 39.8 | 41.7 |
| Llama 1 | 65B | 30.7 | 70.7 | 60.5 | 68.6 | 30.8 | 63.4 | 43.5 | 47.6 |
| Llama 2 | 7B | 16.8 | 63.9 | 48.9 | 61.3 | 14.6 | 45.3 | 32.6 | 29.3 |
| Llama 2 | 13B | 24.5 | 66.9 | 55.4 | 65.8 | 28.7 | 54.8 | 39.4 | 39.1 |
| Llama 2 | 70B | 37.5 | 71.9 | 63.6 | 69.4 | 35.2 | 68.9 | 51.2 | 54.2 |
Ethical Considerations and Limitations
Llama 2, while groundbreaking, is not exempt from the inherent risks associated with new technologies. Our evaluations thus far have been predominantly focused on the English language, and it’s impractical to cover every potential situation. Consequently, just like other LLMs, Llama 2’s output remains somewhat unpredictable. There’s a possibility that the model may sometimes deliver responses that are erroneous, display bias, or are generally objectionable. As a precaution, it’s imperative for developers to conduct comprehensive safety checks and calibration to align Llama 2’s behavior with their specific application requirements before integration.
For a deeper understanding of responsible usage, please refer to the Responsible Use Guide on https://ai.meta.com/llama/responsible-use-guide/.
Read more related topics: