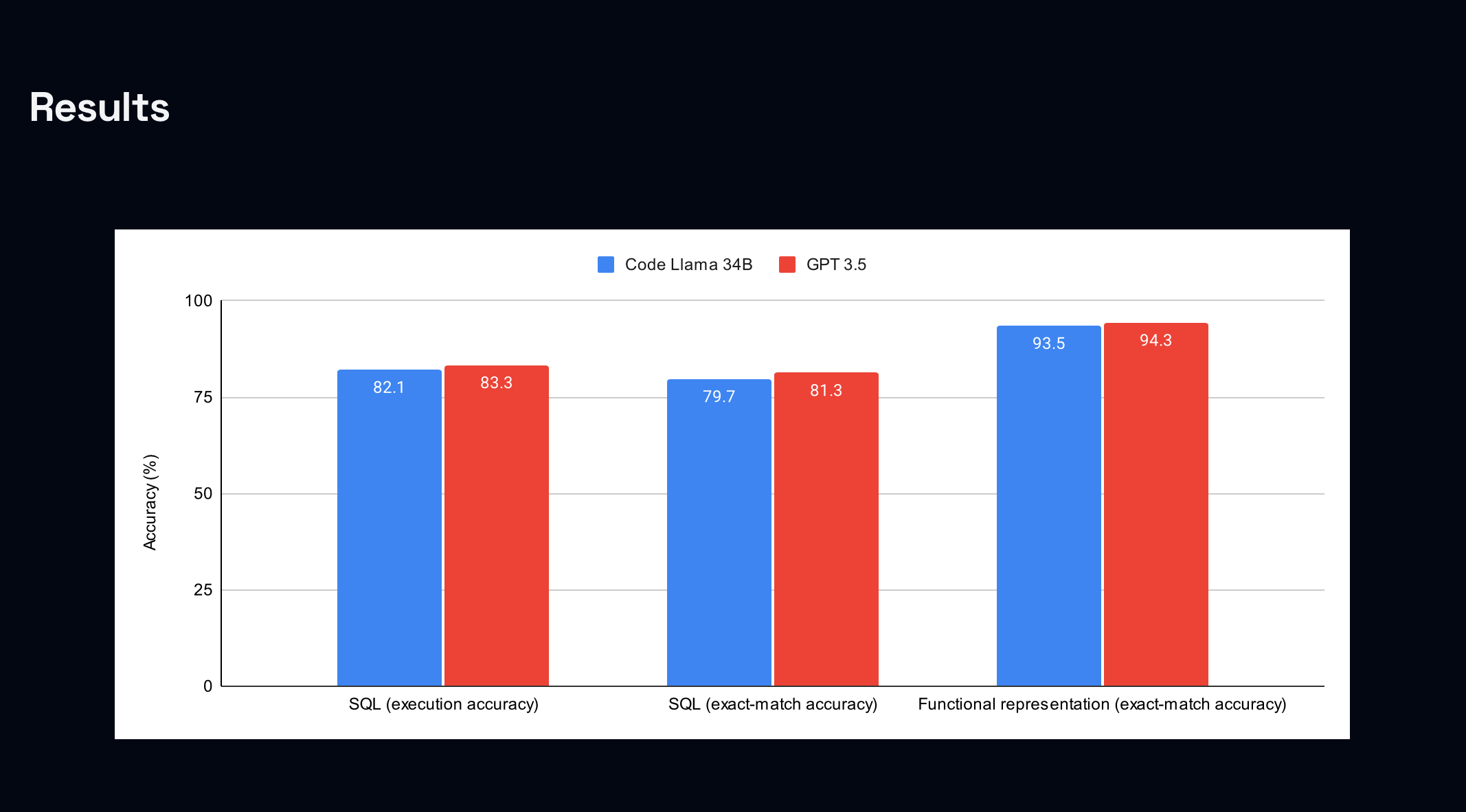
Sam L’Huillier conducted a study on the benchmarking of GPT 3.5 against Llama 2, focusing on an SQL task and a functional representation task. His findings include:
- GPT 3.5 has a slight edge over a Lora fine-tuned CodeLlama 34B in both tasks.
- The cost of training GPT 3.5 is 4-6 times higher than its counterpart and even more for deployment.
- For the SQL task, the code and data can be found here, and for the functional representation task, the details are available here.
The motivation behind the research was to determine if manually fine-tuning models could come close to matching the performance of GPT 3.5, but at a much lower cost. Surprisingly, the results were affirmative.
Comparing the performance of CodeLlama 34B and GPT 3.5 when trained on an SQL task and a functional representation task, GPT 3.5 displayed slightly better accuracy for both tasks. The metrics used for evaluation included execution accuracy, which compares the results of running queries on mock databases, and exact-match accuracy, a character-level comparison.
Pricing
A breakdown of the training costs for the two models was provided:
- SQL spider dataset: Code Llama 34B at $3.32 for a 7-hour job versus GPT 3.5 at $11.99.
- Functional representation dataset: Code Llama 34B at $4.27 for a 9-hour job against GPT 3.5 at $26.05. The reference GPU used was an A40, priced at $0.475 per hour on the vast.ai platform.
Experiment setup
For the experiment setup, a subset of the Spider dataset and the Viggo functional representation dataset were chosen for their teaching capabilities. They focused on structured outputs and did not relay facts. While fine-tuning GPT 3.5, only the number of epochs was configurable, and minimal hyperparameter tuning was done with Llama 2.
As for Llama’s architecture, two significant choices were made: using Code Llama 34B and Lora fine-tuning instead of full-parameter. Lora was chosen based on its comparable performance with full-parameter tuning for tasks like SQL and functional representation.
Datasets used in the study were detailed, including SQL prompts that ask the model to produce SQL queries based on given contexts, as well as functional representation prompts that required the model to construct the underlying meaning representation of input sentences.
Conclusion
In conclusion, Sam L’Huillier’s research suggested that while fine-tuning GPT 3.5 is beneficial for initial validation or MVP work, Llama 2 may be a more cost-effective and flexible choice for long-term projects.
Fine-tuning GPT 3.5 is ideal for tasks or datasets validation and for those seeking a fully-managed experience. On the other hand, an open-source model like Llama 2 is recommended for cost savings, maximizing dataset performance, infrastructure flexibility, and data privacy concerns.
Read related articles: