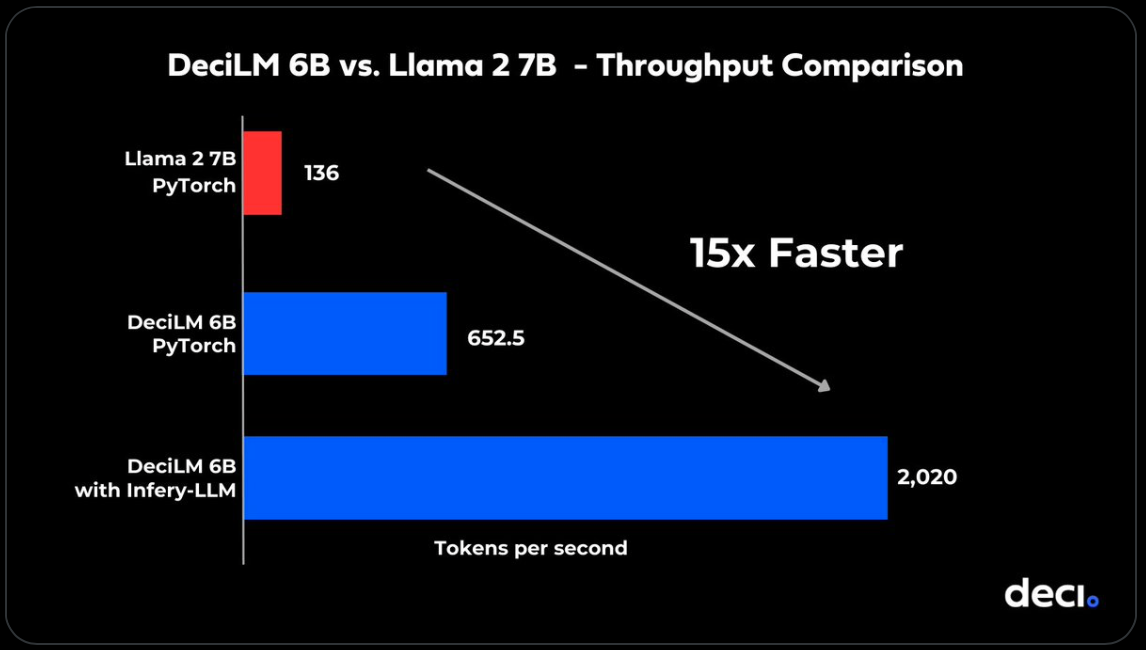
DeciLM is an efficient, blazing-fast text generation language model. DeciLM-6B is 15x faster than Llama 2! Here’s what sets it apart.
What is DeciLM?
DeciLM 6B is a 5.7 billion parameter decoder-only text generation model. With a context window of 4096 tokens, the highly efficient model uses variable Grouped-Query Attention (GQA) to achieve an optimal balance between performance and computational efficiency.
Performance Metrics that Speak Volumes
DeciLM-6B has set a new gold standard, outperforming Llama 2 7B’s throughput by an astonishing 15 times. Experience groundbreaking architecture with AutoNAC – Deci’s avant-garde neural architecture search engine. And that’s not all – when combined with Deci’s inference SDK, the throughput soars to new heights.
A Pioneering Architecture
DeciLM introduces a distinctive, decoder-only transformer architecture that utilizes variable Grouped-Query Attention (GQA). Moreover, it provides dynamic group sizes to enhance adaptability.
Remarkable Benchmarking results
DeciLM outperforms Llama 2 7B, a benchmark-topping powerhouse on ARC, HellaSwag, MMLU, and TruthfulQA. With even fewer parameters, DeciLM dominates the Hugging Face Open LLM Leaderboard.
DeciLM and DeciAI’s Inference SDK are an unstoppable force.
Infery’s Turbocharged CUDA Kernels
Custom kernels optimize grouped query attention, prefill, and generation stages to perfection. Read more about Infery-LLM.
Selective Quantization
Experience FP32 quality while selectively applying FP16 & INT8 quantization. It’s the best of both worlds.
Some key Details:
- Parameters: 5.7 Billion
- Layers: 32 Heads: 32
- Sequence Length: 4096 tokens
- Hidden Size: 4096
- Attention Mechanism: Variable Grouped-Query Attention (GQA)
Read related articles: