
In the experiment conducted by Anyscale, it was discovered that Llama-2-70b is nearly as proficient in factuality as GPT-4 and significantly superior to GPT-3.5-turbo. Anyscale employed their Endpoints to juxtapose Llama 2 7b, 13b, and 70b (chat-hf fine-tuned) against OpenAI’s GPT-3.5-turbo and GPT-4. They utilized a triply-verified, hand-labeled dataset of 373 news report statements, presenting one accurate and one inaccurate summary for each. Each LLM was tasked with determining which statement was the factual summary. Let’s take a look at this LLama 2 vs GPT-4 comparison.
Summary of Findings
Issues Encountered
- Instruction Adherence: Larger models adhered better to given instructions. Smaller LLMs’ outputs were analyzed using another LLM to discern if they chose option A or B.
- Ordering Bias: The position of an option (A or B) can influence selection. This was tested by interchanging the order and observing if the model consistently chose A or B.
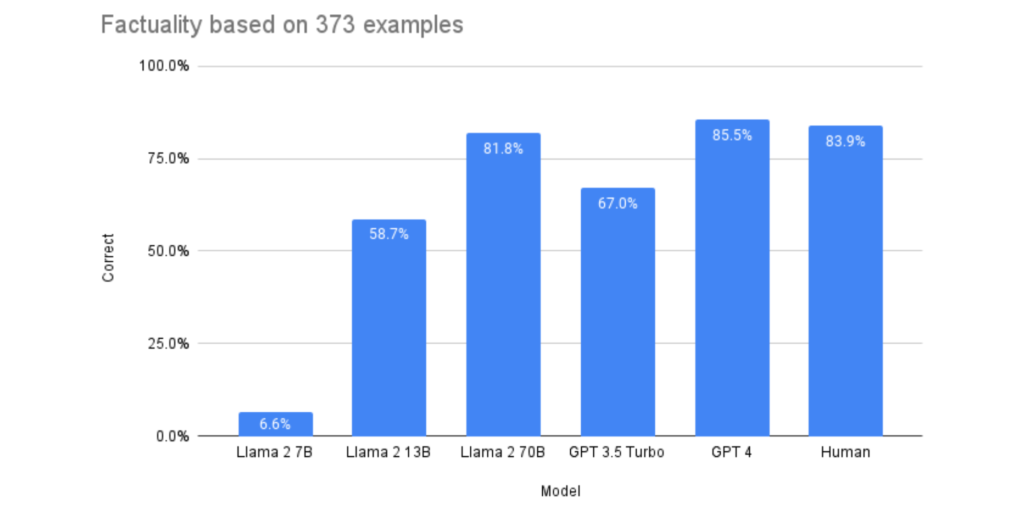
Performance Rates
- Humans: 84% accuracy (based on prior research)
- GPT-3.5-Turbo: 67.0% (displayed strong ordering bias)
- GPT-4: 85.5%
- Llama-2-7b: Extremely low accuracy due to pronounced ordering bias
- Llama-2-13b: 58.9%
- Llama-2-70b: 81.7%
For best factual summarization close to human capability, it is advisable to utilize either Llama-2-70b or GPT-4. While GPT-4 slightly surpassed human accuracy, Llama-2-70b fell a bit short. Llama-2-7b and Llama-2-13b exhibited problems in adhering to the instructions and showed ordering bias. GPT-3.5-Turbo and smaller Llama variants might not be the best choices due to their respective biases.
Additional Observations
- Both GPT-4 and GPT-3.5 outperformed their open-source equivalents in following instructions.
- GPT-3.5 manifested significant ordering bias.
- Llama 2’s tokenization process takes 19% longer than ChatGPT’s, affecting cost considerations. However, Llama 2 offers a 30-fold cost advantage over GPT-4 when considering equivalent factuality in summarization.
Methodology
- The evaluations were conducted efficiently using Anyscale Endpoints.
- Integration of Pandas and Ray (particularly Ray Data) streamlined the experiment, condensing it to roughly 30 lines of code and a 15-minute execution time. An IPython notebook with the details is provided.
Contributions
- Proposing a technique to gauge pairwise ordering bias and a solution (order swapping) to counteract it.
Advice
- LLM users should remain vigilant about ordering bias when presenting options.
- Anyscale Endpoints provides a seamless experience, and Serverless Llama 2 simplifies experimentation.
- For LLM-based experiments, Pandas proves to be highly effective.
- Employing Ray can expedite experimental processes.
LLama 2 vs GPT-4 comparison details
Experiment results
Topic Overview
Summarization is a pivotal application of LLMs, with others including retrieval augmented generation, data interaction, and long-document question answering. While fluency and relevance are vital characteristics for LLMs, factuality remains a challenge, rendering the summaries sometimes misleading despite being well-articulated. A prevailing question is how open-use LLMs, such as Llama 2, fare against well-established products like OpenAI’s GPT-3.5-turbo and GPT-4.
Literature Insights
Contemporary literature reveals LLMs excel in summarization, outperforming earlier summarization systems. Although the focus has predominantly been on GPT-3 or GPT-3.5-turbo, open-source LLMs and GPT-4 haven’t received as much attention. Factuality, ensuring summaries are accurate and consistent with the source, is a major concern. A noteworthy methodology involves prompting an LLM to ascertain the more factually consistent answer. An exemplary dataset with 373 news sentences, each paired with a correct and incorrect summary, was highlighted.
Experimental Consideration
For an effective summary, avoiding factual errors is paramount. Evaluating LLMs based on their ability to discern factual from non-factual sentences might indicate their proficiency in generating accurate summaries. The objective was to assess five LLMs, including three Llama 2 variants, GPT-3.5-turbo, and GPT-4, resulting in almost 2000 queries. Ray simplified the parallelization of such queries. However, the limiting factor was OpenAI’s GPT-4 and GPT-3.5-turbo’s stringent rate restrictions, while Anyscale Endpoints proved more flexible.
Factuality Level
Both Llama-2-70b and GPT-4 exhibit performance that is either at or very close to human standards when it comes to factuality. In a head-to-head comparison for this specific task, they demonstrate roughly equivalent capabilities. The notable takeaway is that the quality difference between open-source LLMs like Llama-2-70b and proprietary models like those from OpenAI is now minimal. In terms of performance, Llama-2-70b decisively surpasses GPT-3.5-turbo.
Given the results of this experiment, the verdict is affirmative: Llama 2’s factuality can be trusted, as its performance aligns closely with human standards.
Bias Challenges
Ordering bias was a prominent issue with Llama-2-7b, GPT-3.5-turbo, and to a lesser degree, Llama-2-13b. This issue was notably absent in the larger models. Such a bias indicates that these models might not be the optimal choice for tasks demanding factuality that’s comparable to human levels.
Future Directions
The upcoming research focus will be on devising strategies to diminish ordering bias, possibly by refining prompt designs.
The “how”
Evaluation Insights
- Ray’s Efficiency: Leveraging Ray considerably accelerated evaluation speeds. What might have taken hours without Ray was reduced to minutes, implying vast potential savings for live AI applications in cloud costs.
- Utility of Pandas: Contrary to its typical association with numerical data, Pandas demonstrated strong efficacy in text processing. Its capacity to swiftly augment columns and apply map functions is invaluable. The fusion of Ray’s computational prowess with Pandas’ data handling and analysis offers a potent synergy.
- Endpoints and APIs: For evaluating the llama models, Anyscale Endpoints was the go-to, whereas OpenAI was employed for the GPT-3.5 and GPT-4 models. Both platforms could run the same code, thanks to the OpenAI-compatible API of Anyscale Endpoints. Notably, Anyscale Endpoints exhibited commendable stability and a generous rate limit, expediting processing and exemplifying how efficient infrastructure can result in substantial cloud cost reductions.
Conclusive Remarks
Factuality Analysis
A side-by-side examination of Open Source and proprietary LLMs was conducted focusing on their factual accuracy in summarization. Llama-2-70b outperformed GPT-3.5-turbo and was on the cusp of matching the factuality levels of humans and GPT-4. This positions Llama-2-70b as a competitive alternative to exclusive LLMs, like OpenAI’s offerings. Thus, using Llama-2-70b or GPT-4 would likely yield human-comparable factuality in outputs.
Data Scrutiny
It’s vital to invest time in comprehending one’s data. Case in point: the ordering bias discovered in GPT-3.5. An overarching principle emerged: if LLM results seem too optimal to be genuine, they likely are. To cap it off, Llama 2’s factual accuracy in summarization rivals GPT-4’s, with the bonus of being 30 times more cost-effective.
Read related topics: