Blog
-

Run LLama 3 on iPhone 15 Pro
In addition to other improvements, current release enables running Meta Llama 2 7B efficiently on devices like the iPhone 15 Pro, Samsung Galaxy S24 and other edge devices — it also includes early support for Llama 3 8B. More details on ExecuTorch Alpha below. ExecuTorch ExecuTorch Alpha is focused on deploying large language models and…
-

LLama 3 vs GPT-4
Llama 3 is a cutting-edge large language model introduced by Meta AI on April 18, 2024. This model family offers three sizes: 8B, 70B, and 400B. The 8B and 70B versions are available to the public, whereas the 400B version is currently undergoing training. Llama 3 boasts benchmark scores that match or surpass those of…
-

Llama-3 Is Not Really Censored
It turns out that Llama-3, right out of the box, is not heavily censored. In the release blog post, Meta indicated that we should expect fewer prompt refusals, and this appears to be accurate. For example, if you were to ask the Llama-3 70 billion model to tell you a joke about women or men,…
-
LLama 3 on Groq
Okay, so this is the actual speed of generation, and we’re achieving more than 800 tokens per second, which is unprecedented. Since the release of LLama 3 earlier this morning, numerous companies have begun integrating this technology into their platforms. One particularly exciting development is its integration with Groq Cloud, which boasts the fastest inference…
-

LLama 3 is HERE
Today marks the exhilarating launch of LLama 3! In this blog post, we’ll delve into the announcement of LLama 3, exploring what’s new and different about this latest model. If you’re passionate about AI, make sure to subscribe to receive more fantastic content. Launch Details and Initial Impressions Just a few minutes ago, we witnessed…
-

Meta Llama 3 70B Model
Meta Llama 3 is out now and available on Replicate. This language model family comes in 8B and 70B parameter sizes, with context windows of 8K tokens. The models beat most other open source models on industry benchmarks and are licensed for commercial use. Llama 3 models include base and instruction-tuned models. You can chat…
-
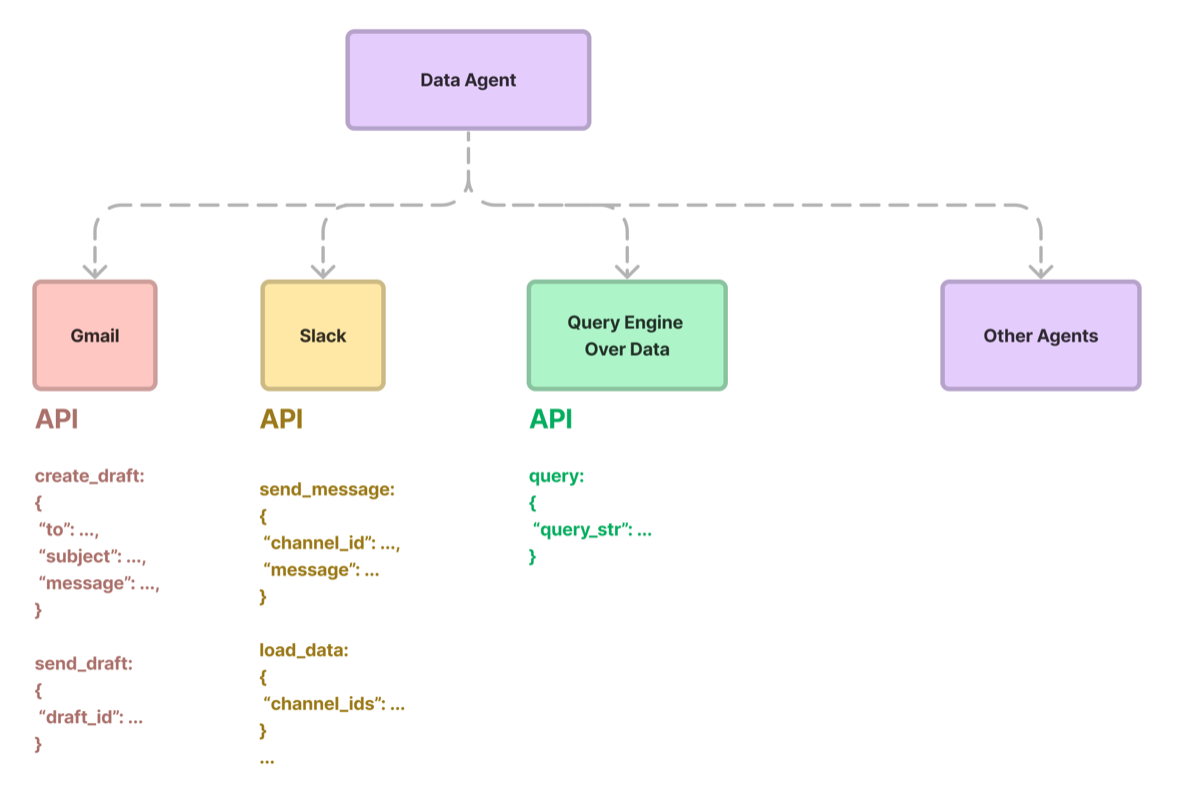
Data Agents
Data Agents, empowered by LLMs are knowledge workers within Llamalndex, designed to interact with various types of data. These agents can handle both unstructured and structured data, significantly enhancing the capabilities beyond traditional query engines. Data Agents High Level Overview Functionality Data Agents can autonomously conduct searches and retrieve information across unstructured, semi-structured, and structured…
-

CodeLLama vs GPT-4
Recently Meta unveiled CodeLLama, a 70-billion-parameter open-source large language model (LLM). This release marks a significant milestone as it introduces the largest and most effective iteration of their LLM to date. CodeLLama is available in three distinct versions: the base model, the Python-specific model finely tuned for Python coding, and the Instruct model, which is…
-

MetaGPT
MetaGPT (Hong et al.) is an awesome multi-agent framework (ICLR 2024) that models agents as a software company following a structured SOP – PMs, architects, engineers, and more communicate with each other to solve the task at hand. LLamaIndex team excited to feature RAG-enhanced MetaGPT, powered by @llama_index modules – this allows agents to tap…