Blog
-

Work with Llama 3.1
Ready to start working with Llama 3.1? Here are a few new resources from the Llama team to help you get started. First thing’s first, get access to all of the latest Llama 3.1 models at: https://llama.meta.com/llama-downloads/. Want to access the code, new training recipes and more? Check out the official Llama repo on GitHub:…
-

Llama 3.1 405B
In April 2024, Meta launched Llama 3, the latest generation of advanced, open-source large language models. The initial release featured Llama 3 8B and Llama 3 70B, both setting new performance benchmarks for LLMs in their respective sizes. However, within three months, several other models surpassed these benchmarks, highlighting the rapid advancements in artificial intelligence.…
-
Multimodal Parsing using Anthropic Claude (Sonnet 3.5)
This cookbook shows you how to use LlamaParse to parse any document with the multimodal capabilities of Claude Sonnet 3.5. LlamaParse allows you to plug in external, multimodal model vendors for parsing – we handle the error correction, validation, and scalability/reliability for you. Setup Download the data. Download both the full paper and also just…
-

Llama-3 on Groq
Excitement surrounds the release of two new open-source models designed specifically for tool use: Llama-3-Groq-70B-Tool-Use and Llama-3-Groq-8B-Tool-Use, built with Meta Llama-3. Developed in collaboration with Glaive, these models mark a significant advancement in open-source AI capabilities for tool use and function calling. Llama-3-Groq-70B-Tool-Use has distinguished itself as the top performer on the Berkeley Function Calling…
-
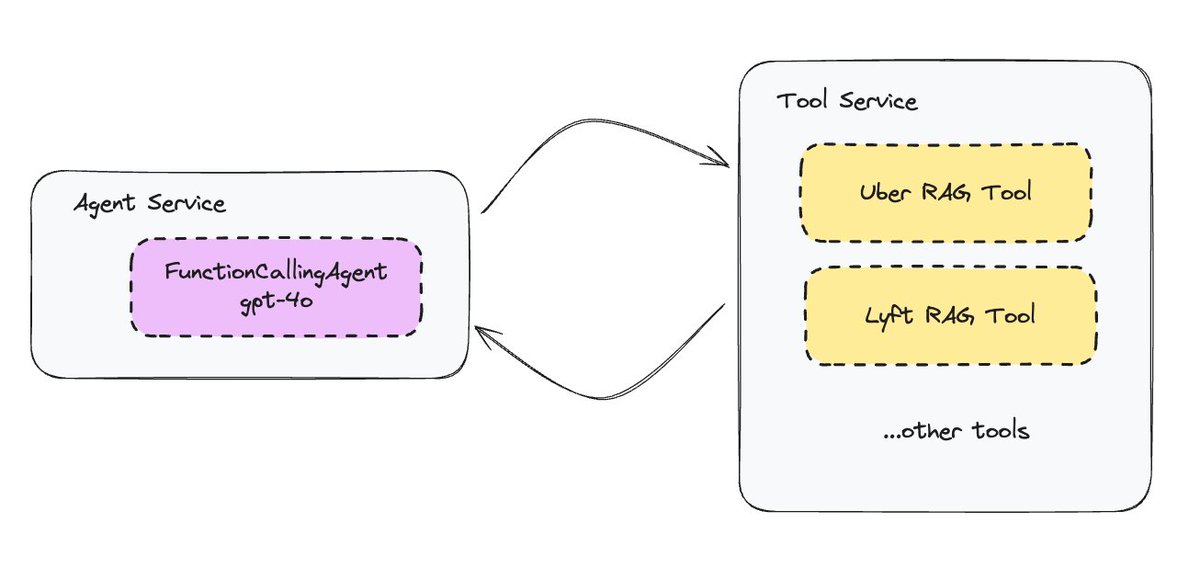
LLama Agents by LLamaIndex
Let’s take the common pattern of agents interacting with tools, and turning them into microservices. In llama-agents we allow you to setup both an agent service, which takes in a user input and performs reasoning about the next task to solve, and also a tool service, which can execute any variety of tools and exposes…
-

Building a Basic AI Agent
In LlamaIndex, an agent is a semi-autonomous piece of software powered by an LLM that is given a task and executes a series of steps towards solving that task. It is given a set of tools, which can be anything from arbitrary functions up to full LlamaIndex query engines, and it selects the best available…
-

How to Use Meta AI
Meta AI has recently been released, offering a range of unique features and functionalities. This tutorial will guide you through the essential aspects of using Meta AI effectively. Whether you’re a beginner or an experienced user, this comprehensive guide will help you navigate the software with ease. Accessing Meta AI Meta AI is currently subject…
-

LLama-3 vs Phi-3
In the ongoing quest to create the most powerful and efficient AI models, a new champion has emerged from the ranks of the small guys. Microsoft’s Phi-3, a tiny AI model by industry standards, has been racking up impressive wins, including surpassing Meta’s much larger LLama-3 model in key benchmarks. This development suggests a shift…
-
LlamaFS
Today’s highlight is LlamaFS – a self-organizing file manager. Given a directory of messy files (e.g. your ~/Downloads directory), it will automatically and reorganize the entire set of files into an organized directory structure with interpretable names. It can “watch” your directory and intercept all FS operations to proactively learn how you rename files. It’s…