Meta team unveiled Llama 2, which includes a series of pretrained and fine-tuned large language models (LLMs) with parameter counts ranging from 7 billion to 70 billion. Specifically, their fine-tuned variants, termed Llama 2-Chat, are tailored for dialogue applications. These models surpass most open-source chat models on several benchmarks they assessed. In this article we will review in details LLama 2 Training, Meta’s fine-tuned models, Llama 2-Chat, which tailored for dialogue applications
After human evaluations considering helpfulness and safety, it seems that they might be adequate alternatives to proprietary models. They present a detailed report on their fine-tuning and safety improvements for Llama 2-Chat. Their goal is to enable the AI community to build on their work and promote responsible LLM development.
Introduction
Figure 1 presents the results of human evaluations on the helpfulness of Llama 2-Chat in comparison with other open-source and proprietary models. Human evaluators assessed the output from various models on roughly 4,000 prompts, which included both single and multi-turn interactions. The confidence interval for this assessment stands at 95% and ranges from 1% to 2%. A deeper dive into this can be found in Section 3.4.2. It’s crucial to understand when interpreting these results that human evaluations may be subject to variability due to factors like the constraints of the prompt set, the interpretative nature of the review guidelines, individual evaluator biases, and the inherent challenges associated with comparing model outputs.
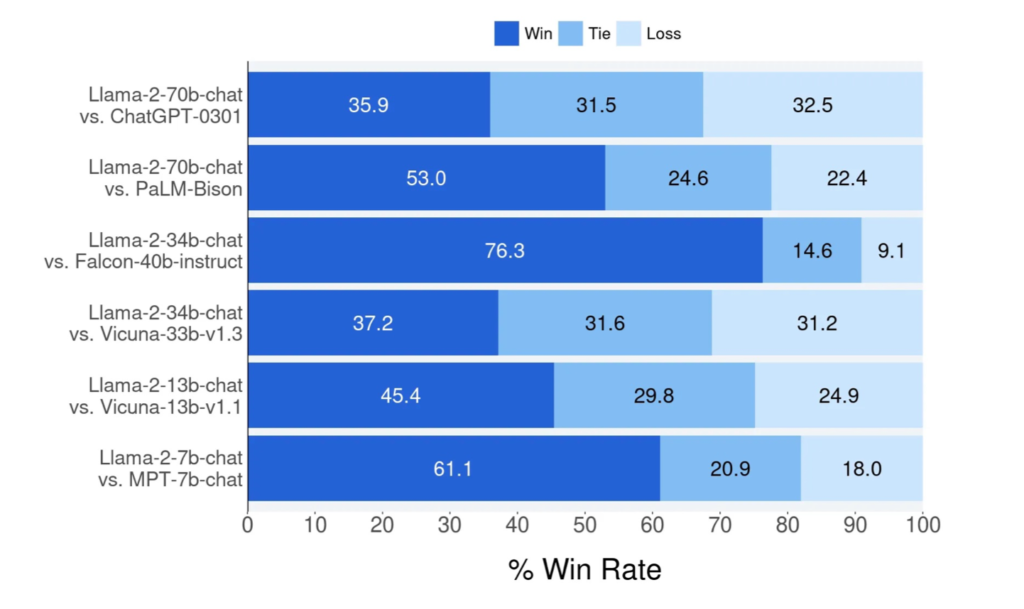
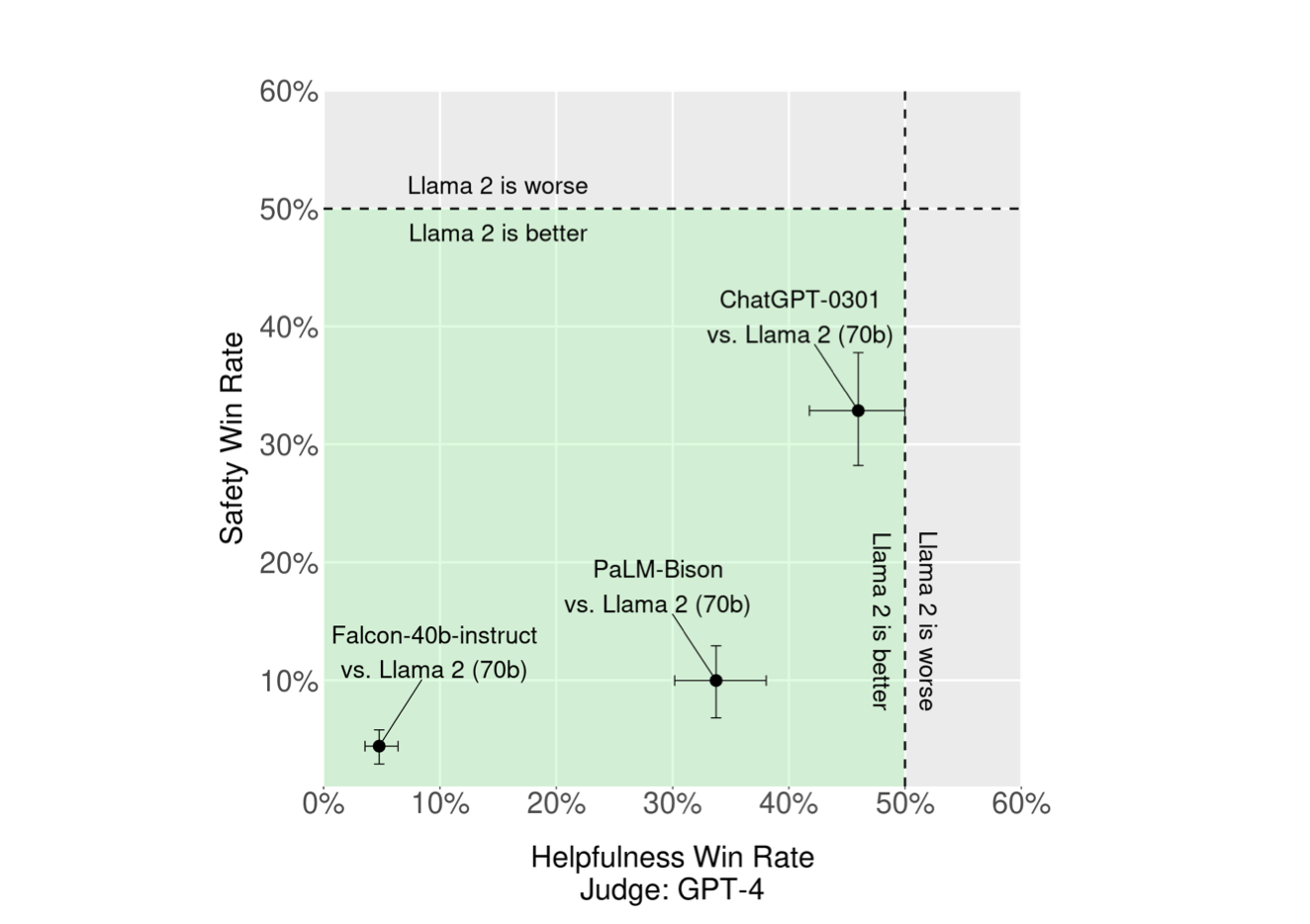
Figure 2 showcases the comparison in terms of helpfulness and safety between commercially licensed models and Llama 2-Chat, as evaluated by GPT-4. Alongside human assessments, they engaged a more proficient model independent of their own oversight. The green section denotes where their model excels per GPT-4’s assessment. To counteract potential ties, they employed the win/(win + loss) metric, ensuring the presentation order to GPT-4 was random to minimize bias.
LLMs, with their ability to adeptly handle intricate reasoning tasks across diverse domains, are gradually emerging as leading AI assistants. Their appeal lies in their capacity to communicate with humans through conversational interfaces, leading to a surge in popularity among mainstream users. The prowess of LLMs is even more astounding given the seemingly direct training approach they employ.
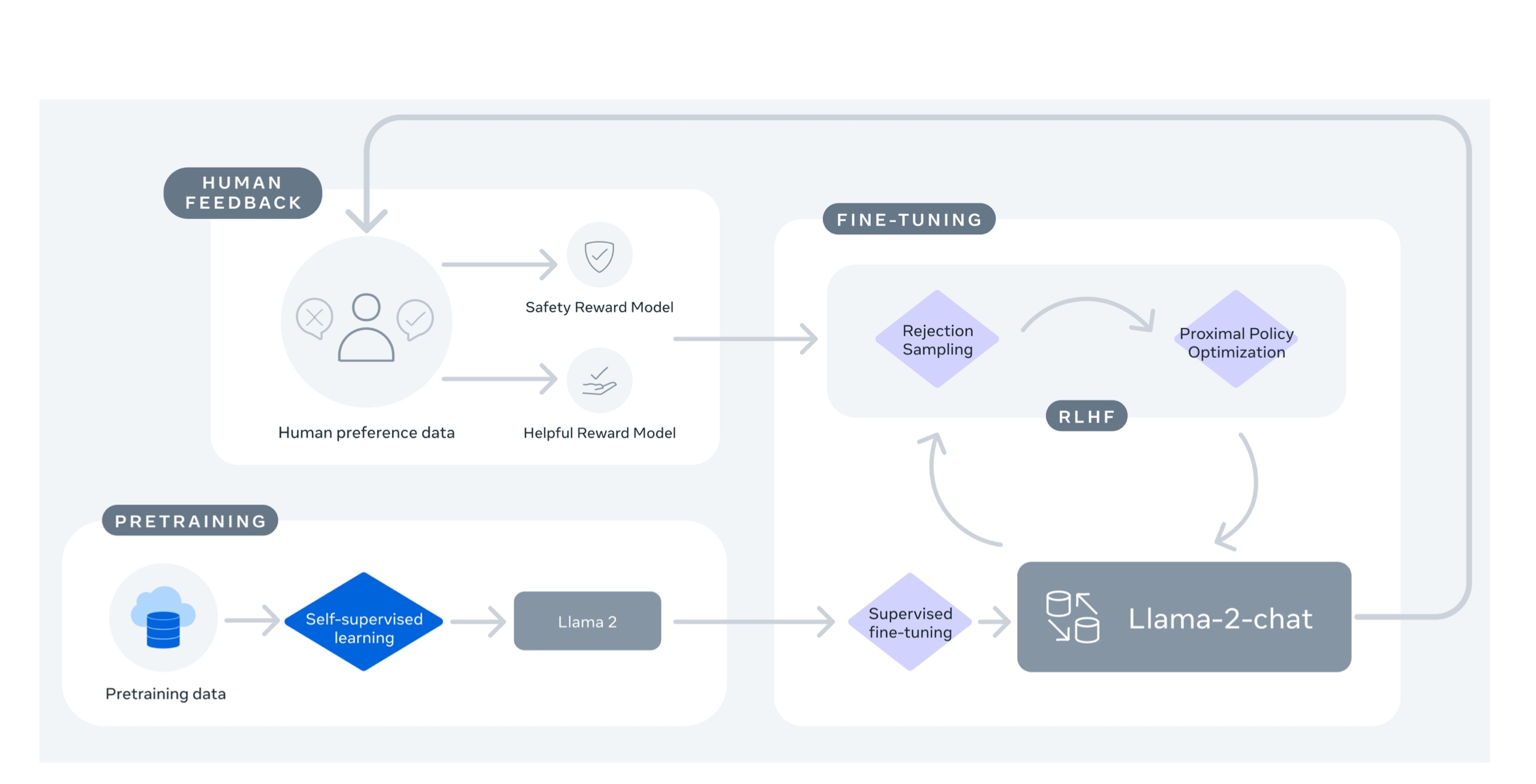
Auto-regressive transformers first train on a large self-supervised data set. Then, they fine-tune to align with human preferences using techniques like Reinforcement Learning with Human Feedback (RLHF). Even though the training process is straightforward, the computational demands often restrict LLM development to a select few.
Model History
Previously released LLMs, such as BLOOM (Scao et al., 2022), LLaMa-1 (Touvron et al., 2023), and Falcon (Penedo et al., 2023), rival the performance of proprietary models like GPT-3 (Brown et al., 2020) and Chinchilla (Hoffmann et al., 2022). However, none truly match the specialized closed “product” LLMs, including ChatGPT, BARD, and Claude, which undergo intensive fine-tuning to synchronize with human expectations, thereby enhancing their usability and security. This alignment process, which often demands substantial computational and human resources, is seldom transparent or replicable, posing hurdles for community-driven advancements in AI alignment.
Within the scope of their research, the team at Meta launched Llama 2, comprised of Llama 2 and Llama 2-Chat, boasting up to 70B parameters. Their tests on safety and helpfulness benchmarks reveal that Llama 2-Chat typically outpaces most extant open-source models and seemingly matches certain proprietary models, as validated by their human-led evaluations (refer to Figures 1 and 3).
Efforts were made to bolster the safety of these models by using safety-specific data annotations, tuning, red-teaming, and periodic evaluations. Furthermore, they offer an in-depth exploration of their fine-tuning strategies and the measures they took to advance LLM safety. Through this transparency, they aspire to empower the community to reproduce and further refine LLMs, steering the path for more ethical LLM advancements. They also shed light on novel findings observed during Llama 2 and Llama 2-Chat’s evolution, such as the spontaneous appearance of tool utilization and the chronological structuring of knowledge.
Human evaluation in LLama 2 Training
Figure 3 showcases the outcomes of human evaluations concerning the safety of Llama 2-Chat, juxtaposed against other open-source and proprietary models. Human evaluators assessed model outputs for potential safety infringements using approximately 2,000 adversarial prompts, incorporating both single and multi-turn interactions.
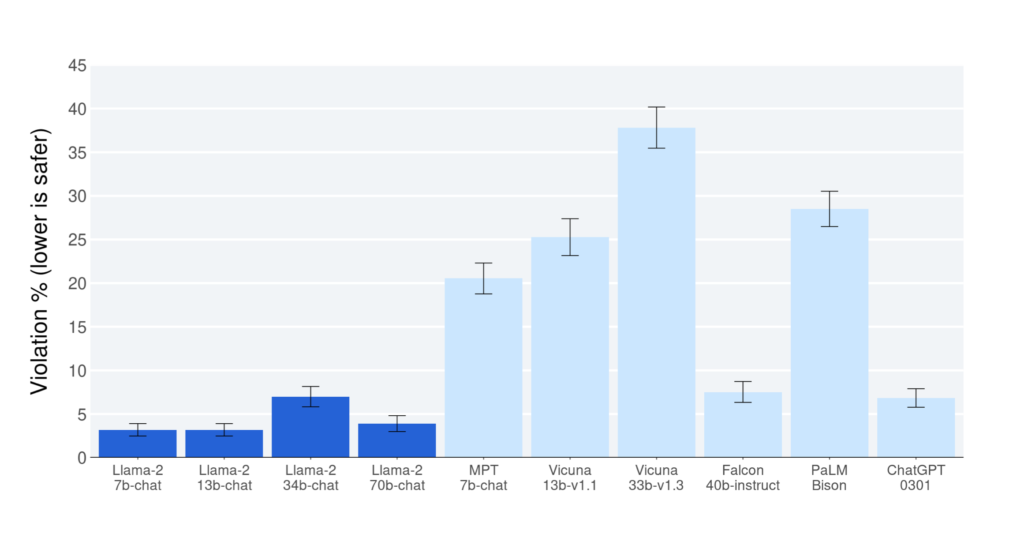
Further insights into this analysis are elaborated in next article. When interpreting these safety outcomes, it’s pivotal to be aware of the intrinsic biases that might plague LLM evaluations. Such biases could stem from the confines of the prompt set, the interpretative nature of the review guidelines, and individual evaluator biases. Furthermore, it should be noted that the benchmarks used for these safety evaluations might inherently favor the Llama 2-Chat models, thereby potentially skewing the results.
Llama-2 Models
The team is making available the subsequent models for public access, catering to both research and commercial purposes‡:
- Llama 2, a refined iteration of its predecessor, Llama 1. They improved the model by using a new mix of public data. They expanded the pretraining dataset by 40%, doubled the model’s context length, and added grouped-query attention, as mentioned by Ainslie et al., 2023. Available variants of Llama 2 include models with 7B, 13B, and 70B parameters. Also, Meta developed 34B parameter versions and discussed them in the paper, but they won’t release these to the public.
- Llama 2-Chat. This represents a finely-tuned version of Llama 2, specifically engineered for dialogue-centric applications. Accessible variants of this model will also come with 7B, 13B, and 70B parameters.
The team stands by the conviction that LLMs, when introduced to the public responsibly, can significantly benefit society at large. However, like its counterparts, Llama 2, as an innovative technological advancement, doesn’t come without its share of potential hazards (as highlighted by Bender et al., 2021b; Weidinger et al., 2021; Solaiman et al., 2023).
Current tests have been predominantly English-centric and certainly can’t account for every conceivable use-case scenario. As a result, before adding Llama 2-Chat to any projects, developers should strongly consider conducting thorough safety evaluations and making adjustments tailored to their model application. To support responsible use, they provided a guide and illustrative code sample to ensure the secure deployment of both Llama 2 and Llama 2-Chat.
LLama 2 Pretraining
The creation of the Llama 2 models began with the methods from Touvron et al. (2023). They adopted an optimized auto-regressive transformer, making multiple enhancements. These included improved data cleaning and refreshed data mixes. They boosted training by 40% more tokens and doubled context length. Additionally, they integrated grouped-query attention (GQA) for better scalability. Table 1 contrasts the Llama 2 features against those of Llama 1.
Pretraining Data
Their corpus relied on publicly available data, excluding any from Meta’s products. Data from sites rich in personal info was deliberately excluded. Their training encompassed 2 trillion tokens, aiming for a balance between performance and cost. By up-sampling factual sources, they aimed to amplify knowledge and suppress inaccuracies. Their pretraining data research was to aid users in understanding the models.
Training Details
They predominantly maintained the pretraining settings and structure from Llama 1. Meta based their model on the standard transformer architecture by Vaswani et al. They also included RMSNorm by Zhang and Sennrich, 2019, and SwiGLU activation by Shazeer, 2020. Rotary positional embeddings (RoPE by Su et al., 2022) were also a part. Key changes in Llama 2 were the extended context and GQA.
Hyperparameters
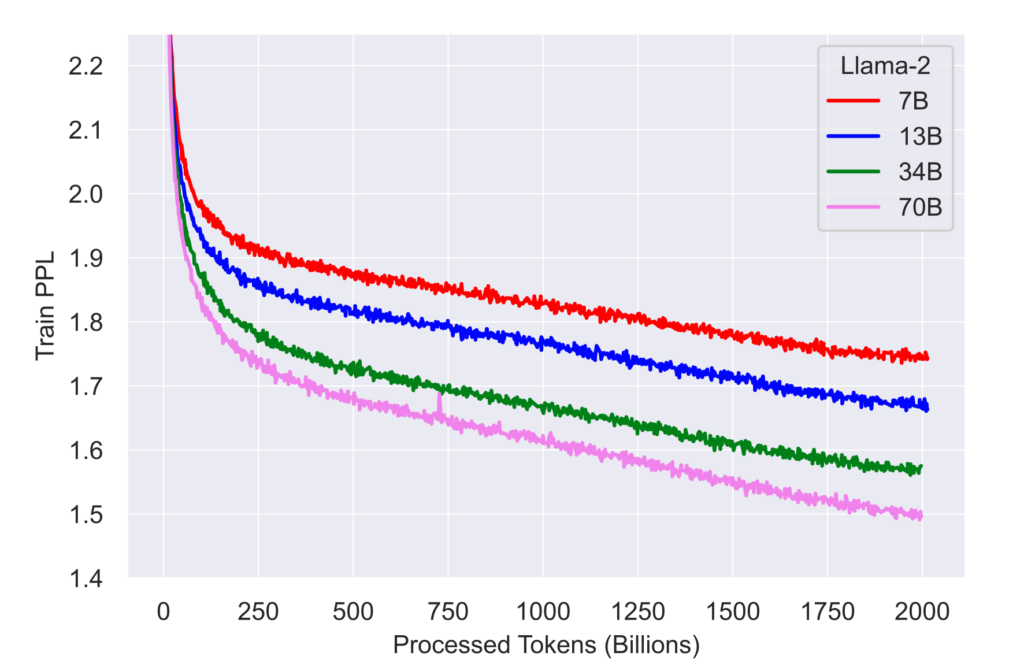
The team employed the AdamW optimizer (referenced to Loshchilov and Hutter, 2017). Configurations were set to β1 = 0.9, β2 = 0.95, and eps = 10−5. A cosine learning rate was used, with a 2000-step warmup phase. The final rate was tapered to 10% of the peak rate. They set the weight decay at 0.1 and capped gradient increments at 1.0. Figure 5 (a) showcases the training loss trajectory for Llama 2.
Tokenizer
Meta employ the same tokenizer as used in Llama 1, which utilizes the bytepair encoding (BPE) method (referenced to Sennrich et al., 2016) from the SentencePiece implementation (attributed to Kudo and Richardson, 2018). Similar to Llama 1 practices, they divide all numbers into separate digits and deploy bytes to break down unfamiliar UTF-8 characters. The entire vocabulary encompasses 32k tokens.
Read more related articles: