Philipp Schmid and his team at HuggingFace highlighted the challenges in deploying large language models (LLMs) and other generative AI models because of their computational demands and latency considerations. They crafted a detailed benchmark that scrutinized over 60 distinct deployment configurations for Llama 2, aiming to aid companies keen on deploying this model on Amazon SageMaker with the Hugging Face LLM Inference Container.
In their benchmark, they assessed the various sizes of Llama 2 across an array of Amazon EC2 instance types under different load conditions. Their intent was to clock latency (ms per token) and throughput (tokens per second) to pinpoint the best deployment tactics for three prevalent scenarios:
- Most Cost-Effective Deployment
- Targeted for users seeking competent performance without burning a hole in their pockets.
- Best Latency Deployment
- Tailored to reduce latency, catering to real-time services.
- Best Throughput Deployment
- Designed to amplify the number of tokens processed each second. To ensure the benchmark remained unbiased, open, and replicable, they disclosed every asset, piece of code, and data they utilized and amassed, including a GitHub repository, raw data, and a spreadsheet filled with processed information.
They expressed their aspiration to streamline the deployment and use of LLMs and Llama 2 to cater to diverse requirements. Before diving deep into the benchmark and data, the team introduced the technologies and methodologies they employed.
What is the Inference Container?
The Hugging Face LLM Inference Container is a specially crafted Inference Container built to seamlessly deploy LLMs in a safeguarded and governed environment. This DLC thrives on Text Generation Inference (TGI), a distinct open-source solution dedicated to the deployment and service of LLMs.
TGI boasts of its prowess in efficient text generation, using Tensor Parallelism and dynamic batching for top-tier open-source LLMs like StarCoder, BLOOM, GPT-NeoX, Falcon, Llama, and T5. Esteemed companies like VMware, IBM, Grammarly, Open-Assistant, Uber, Scale AI, and many others have already incorporated Text Generation Inference.
What is Llama 2?
Llama 2 as a lineage of LLMs from Meta, trained on a staggering 2 trillion tokens. This model is available in three sizes – 7B, 13B, and 70B parameters, bringing forth notable enhancements such as extended context length, commercial licensing, and refined chat capabilities via reinforcement learning in comparison to its predecessor, Llama 1, introduced on February 24th, 2023.
What is GPTQ?
HuggingFace also introduced GPTQ, a technique post-training for the quantization of LLMs, similar to GPT. This method compresses GPT (decoder) models by significantly reducing the bits required to save each weight in the model, plummeting from 32 bits to a mere 3-4 bits. This translates to a model that’s more memory-efficient and can operate on minimal hardware, for instance, a Single GPU for 13B Llama2 models.
Benchmark
For the benchmark, they tested Llama 2 across three model sizes on four distinct instance types under four varied load conditions, culminating in 60 unique configurations. Their metrics revolved around Throughput and Latency.
They shared their insights, indicating that based on their findings, specific recommendations were made for optimal LLM deployment, contingent on one’s priorities among cost, throughput, and latency for all sizes of Llama 2.
Most Cost-Effective Deployment
The optimal cost-effective setup that Philipp Schmid and his team at HuggingFace identified aims for a harmonious balance between performance metrics (latency and throughput) and expense. Their primary objective was to maximize the output for every dollar expended. They scrutinized the performance during situations with 5 simultaneous requests. Their observations indicated that GPTQ stands out in terms of cost-effectiveness, enabling users to deploy the Llama 2 13B model using just one GPU.
| Model | Quantization | Instance | Concurrent Requests | Latency (ms/token) Median | Throughput (tokens/second) | On-demand cost ($/h) in us-west-2 | Time to generate 1M tokens (minutes) | Cost to generate 1M tokens ($) |
|---|---|---|---|---|---|---|---|---|
| Llama 2 7B | GPTQ | g5.2xlarge | 5 | 34.245736 | 120.0941633 | $1.52 | 138.78 | $3.50 |
| Llama 2 13B | GPTQ | g5.2xlarge | 5 | 56.237484 | 71.70560104 | $1.52 | 232.43 | $5.87 |
| Llama 2 70B | GPTQ | ml.g5.12xlarge | 5 | 138.347928 | 33.33372399 | $7.09 | 499.99 | $59.08 |
Best Latency Deployment
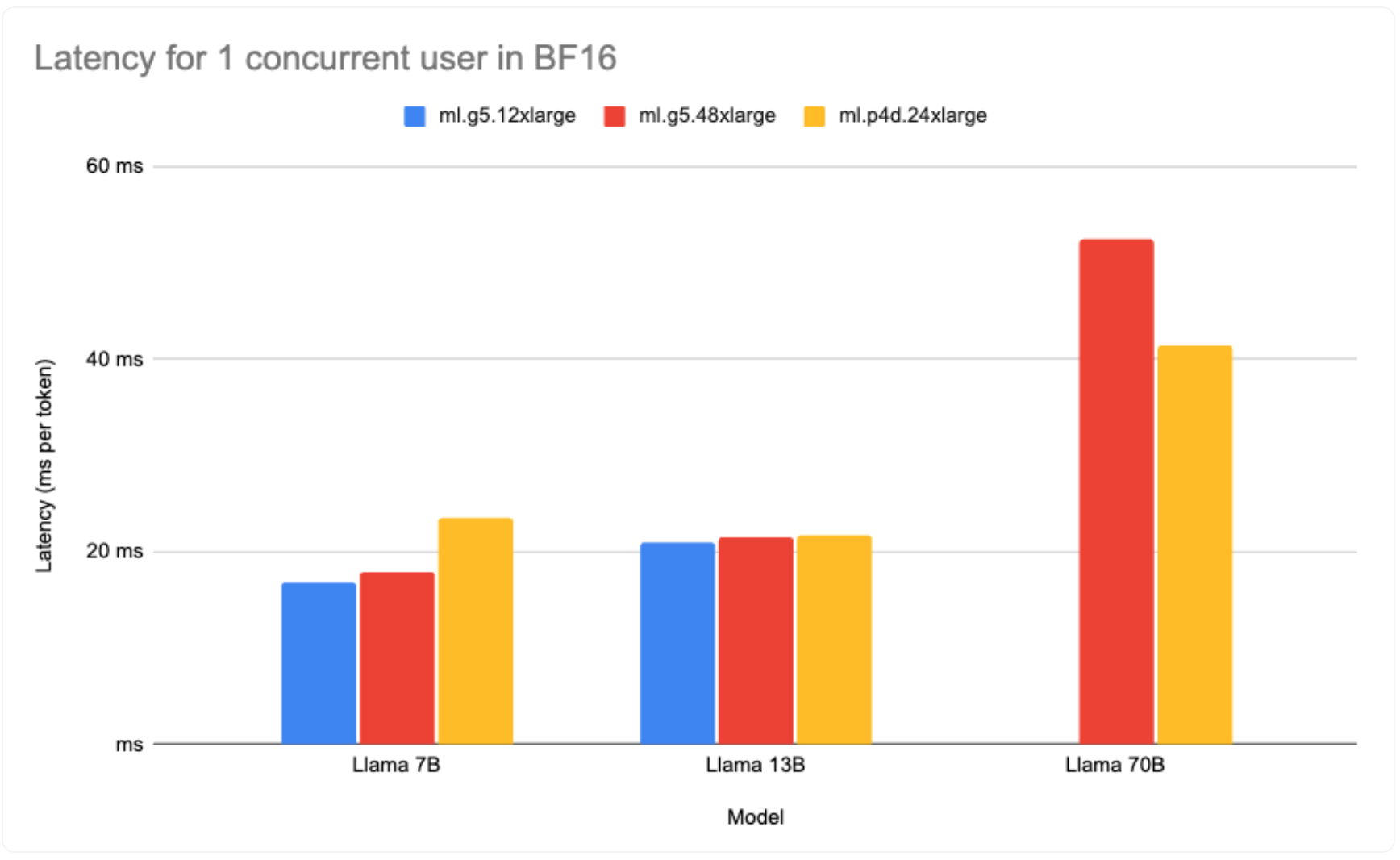
The Best Latency setup prioritizes reducing the time required to produce a single token. Ensuring minimal latency is crucial for real-time applications, such as chat platforms, to offer a seamless experience to users. They centered their analysis on the most minimal median value for milliseconds per token in scenarios with a single concurrent request. Their observations pinpointed that the Llama 2 7B model, when deployed on the ml.g5.12xlarge instance, recorded the lowest latency, clocking in at 16.8ms per token.
| Model | Quantization | Instance | Concurrent Requests | Latency (ms/token) Median | Throughput (tokens/second) | On-demand cost ($/h) in us-west-2 | Time to generate 1M tokens (minutes) | Cost to generate 1M tokens ($) |
|---|---|---|---|---|---|---|---|---|
| Llama 2 7B | None | ml.g5.12xlarge | 1 | 16.812526 | 61.45733054 | $7.09 | 271.19 | $32.05 |
| Llama 2 13B | None | ml.g5.12xlarge | 1 | 21.002715 | 47.15736567 | $7.09 | 353.43 | $41.76 |
| Llama 2 70B | None | ml.p4d.24xlarge | 1 | 41.348543 | 24.5142928 | $37.69 | 679.88 | $427.05 |
Best Throughput Deployment
The Best Throughput setup aims to enhance the generation rate of tokens every second. This configuration might lead to a slight decrease in overall latency, given the simultaneous processing of a greater number of tokens. They focused on the peak performance in terms of tokens per second during scenarios with twenty concurrent requests, while also considering the associated instance costs. Their findings revealed that the Llama 2 13B model, when deployed on the ml.p4d.24xlarge instance, achieved the highest throughput with a rate of 688 tokens/sec.
| Model | Quantization | Instance | Concurrent Requests | Latency (ms/token) Median | Throughput (tokens/second) | On-demand cost ($/h) in us-west-2 | Time to generate 1M tokens (minutes) | Cost to generate 1M tokens ($) |
|---|---|---|---|---|---|---|---|---|
| Llama 2 7B | None | ml.g5.12xlarge | 20 | 43.99524 | 449.9423027 | $7.09 | 33.59 | $3.97 |
| Llama 2 13B | None | ml.p4d.12xlarge | 20 | 67.4027465 | 668.0204881 | $37.69 | 24.95 | $15.67 |
| Llama 2 70B | None | ml.p4d.24xlarge | 20 | 59.798591 | 321.5369158 | $37.69 | 51.83 | $32.56 |
Conclusion
Lastly, in their study, they analyzed 60 configurations of Llama 2 on Amazon SageMaker. Their findings pointed to the most cost-effective, maximum throughput, and minimum latency configurations for Llama 2. They concluded by expressing their hopes that their benchmark would serve as a guide for businesses to efficiently deploy Llama 2 according to their specific requirements.
Read related articles: