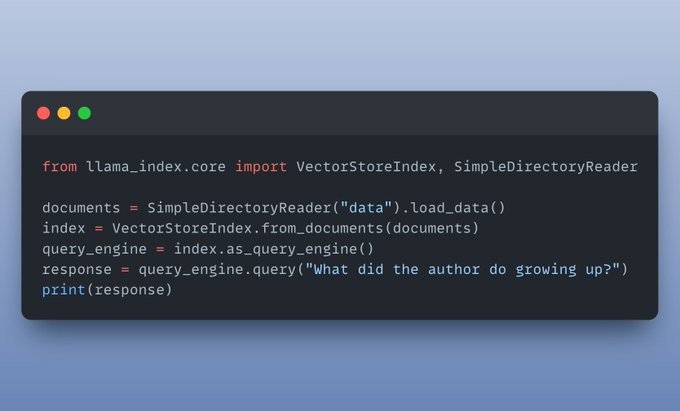
Here’s a minimal implementation of a Document Chat RAG application, all in just 6 lines of code! Now let’s customize it step by step.
I want to parse my documents into smaller chunks.
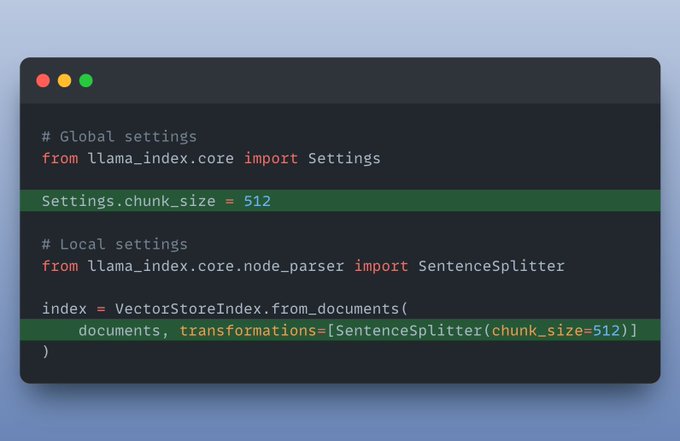
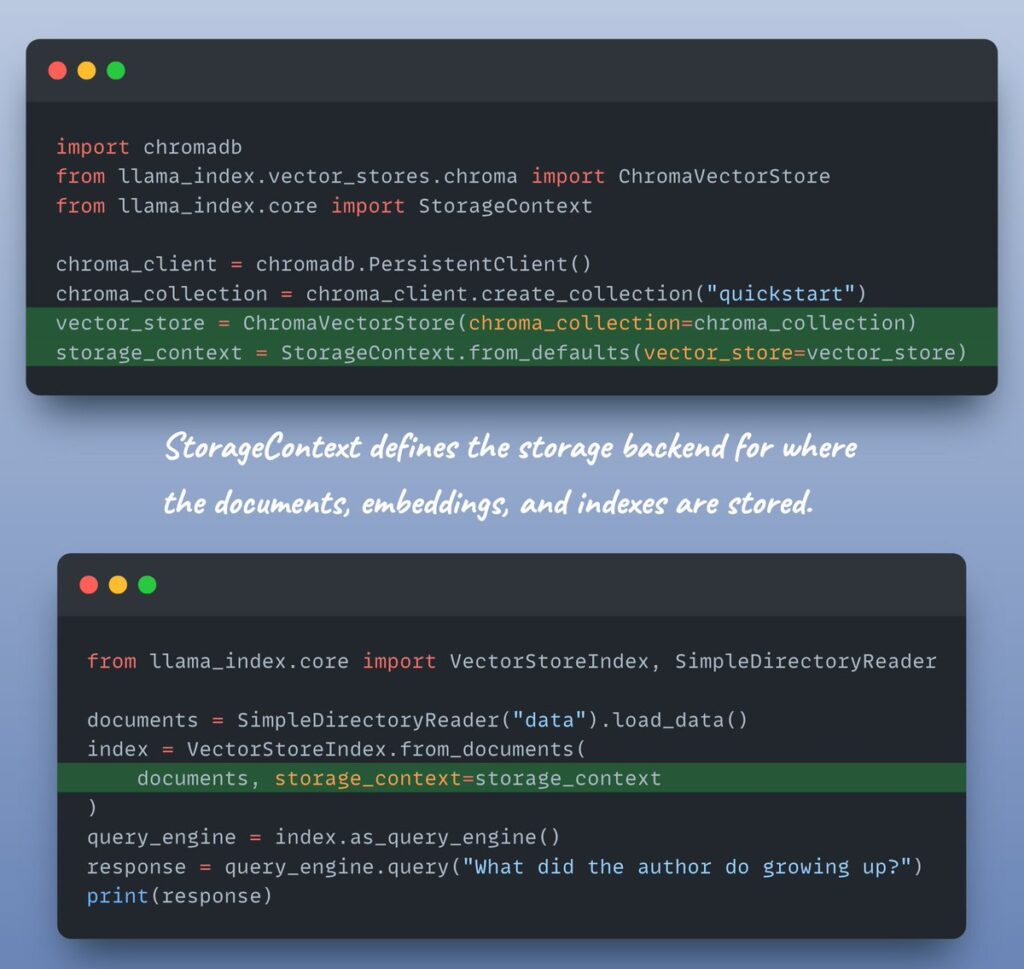
I want to use a different vector store: First, you can install the vector store you want to use. For example, to use Chroma as the vector store, you can install it using pip. `!pip install llama-index-vector-stores-chroma` Then, you can use it in your code:
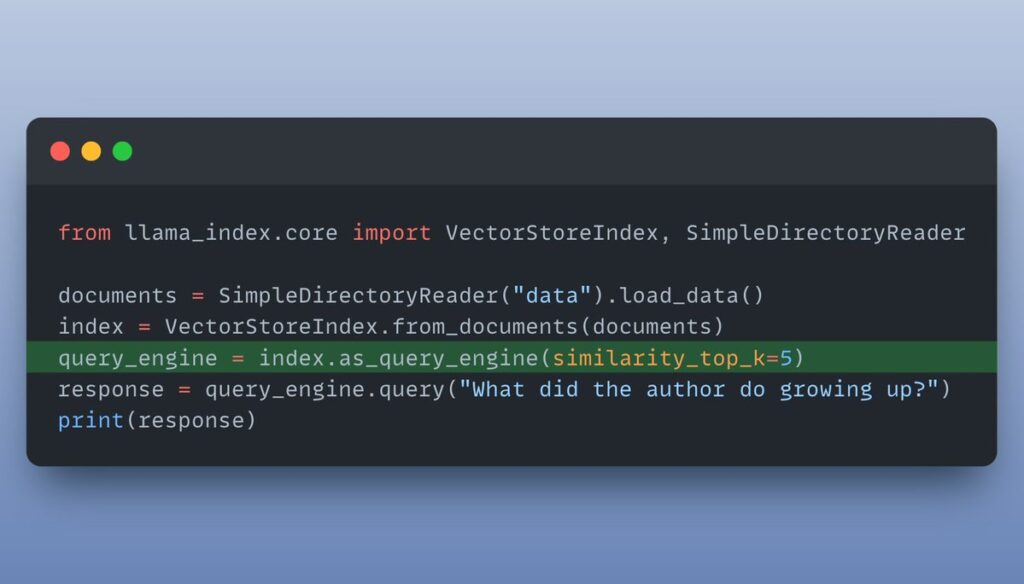
I want to retrieve more context when I query: `as_query_engine()` builds a default `retriever` and `query engine` on top of the index. You can configure them with keyword arguments to return top 5 similar documents instead of the default 2. Check this out below:
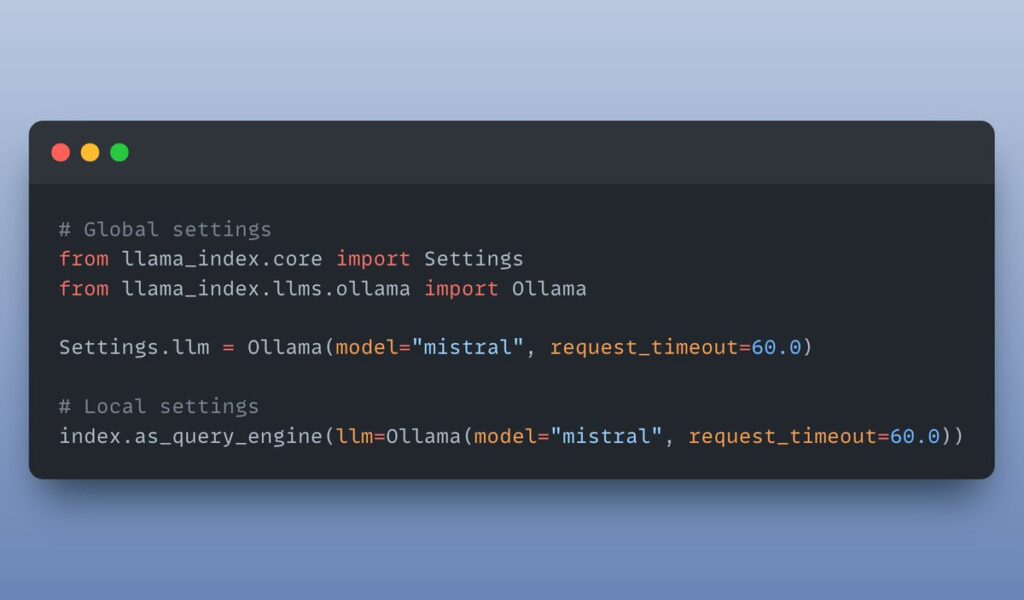
I want to use a different LLM: Thanks to Ollama & it’s integration with LlamaIndex, using custom local LLMs is a cake walk!
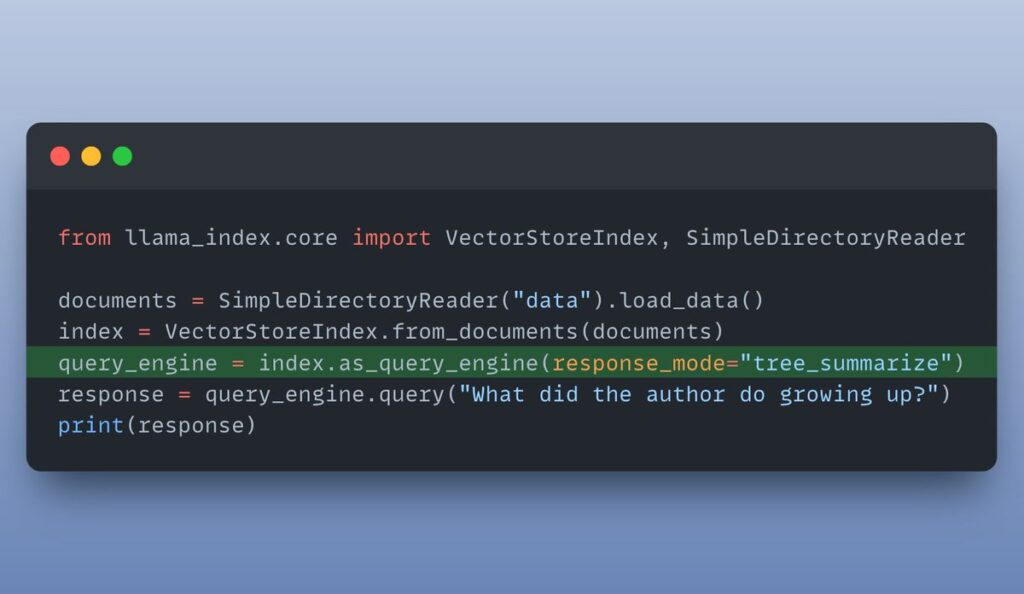
I want to use a different response mode. There are multiple response modes available:
- – refine
- – compact
- – tree_summarize
- – accumulate
- – and you can find more info in the LlamaIndex docs
It’s really simple to use it:
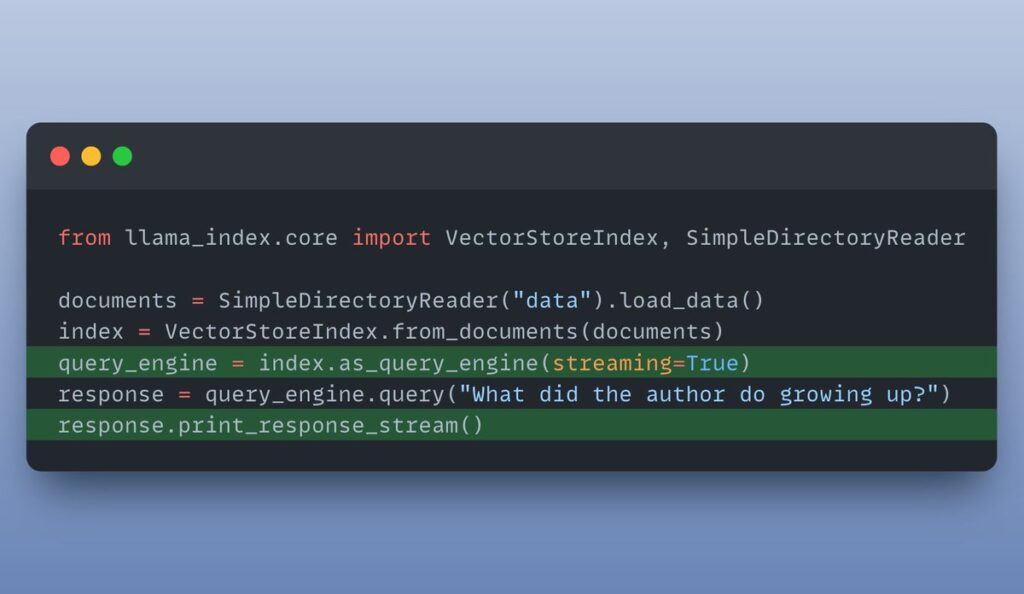
I want to stream the response back. When you do this, you don’t have to wait for the entire response to be generated by the LLM. Just stream the tokens as outputted by the LLM! This makes Chatbot applications really cool!
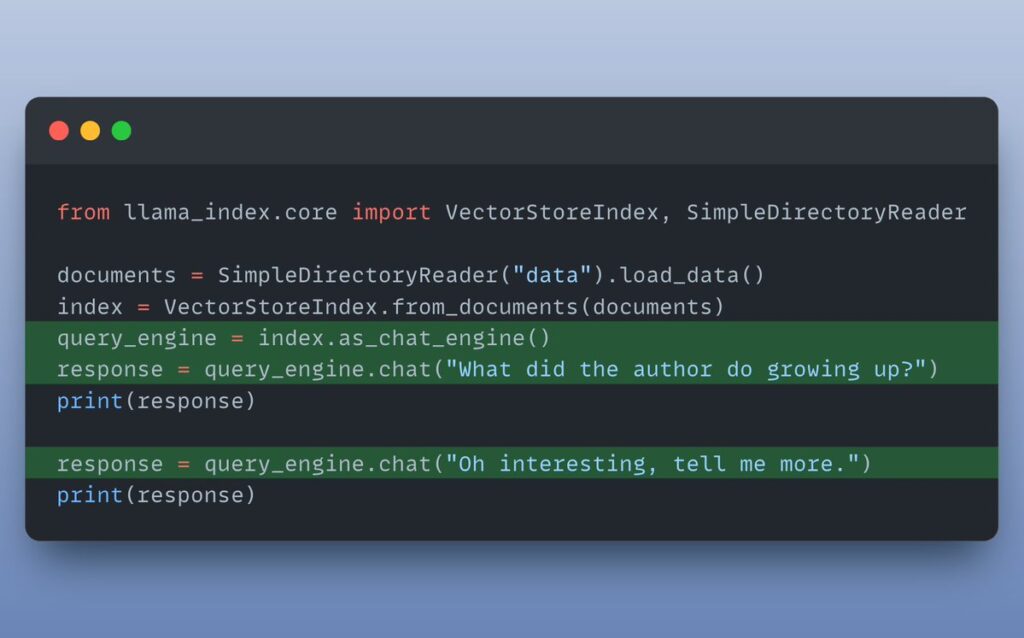
I want a chatbot instead of Q&A:
Hope you enjoyed reading!
Credits: @Akshay
Read related articles: