
Today marks a significant milestone in the LlamaIndex ecosystem with the unveiling of LlamaCloud, the latest offering in managed parsing, ingestion, and retrieval services. This innovation is tailored to enhance the capabilities of your LLM and RAG applications by providing them with production-level context-augmentation. LlamaCloud enables enterprise AI engineers to concentrate on developing business logic rather than spending time on data management. It processes vast amounts of production data swiftly, resulting in improved response quality. The launch of LlamaCloud introduces essential components such as:
- LlamaParse: A unique parsing tool for intricate documents containing tables, figures, and other embedded objects. LlamaParse seamlessly connects with LlamaIndex’s ingestion and retrieval services, facilitating the construction of retrieval systems over semi-structured documents. This allows for the answering of complex queries that were previously unattainable.
- Managed Ingestion and Retrieval API: This API simplifies the process of loading, processing, and storing data for RAG applications, making it accessible in any programming language. It leverages data sources from LlamaHub, inclusive of LlamaParse and our data storage solutions.
Starting today, LlamaParse is accessible in a public preview, with current capabilities extending to PDFs and usage limits for public consumption; we invite inquiries for commercial terms. The managed ingestion and retrieval API is in a private preview phase, available to a select group of enterprise design partners.
RAG’s Potential Relies on Quality Data
The essence of LLMs lies in their power to automate the search, synthesis, extraction, and planning across diverse sources of unstructured data. A novel data stack has evolved over the past year to support these context-enhanced LLM applications, known as Retrieval-Augmented Generation (RAG). This stack, which involves data loading, processing, embedding, and integration into a vector database, is pivotal for the orchestration of retrieval and prompting within LLM applications. This framework is a departure from traditional ETL stacks, as every decision made impacts the accuracy of the LLM-powered system, from chunk size to the choice of embedding model.
Over the past year, we’ve been at the forefront of developing tools and educating our users on creating effective, high-performing RAG applications for various scenarios. With over 2 million monthly downloads, our tools are utilized by a wide range of users, from large enterprises to startups.
Despite the simplicity of starting with our well-known 5-line starter example, crafting production-ready RAG applications poses its own set of intricate challenges. Through numerous discussions with our users, we’ve identified several critical pain points, such as the accuracy of results, the overwhelming number of parameters to adjust, the complexity of handling PDFs, and the challenges of data synchronization.
Solving Problems with LlamaCloud
LlamaCloud and LlamaParse were developed as data pipelines to streamline the journey of bringing your RAG application into production.
LlamaParse
LlamaParse represents the cutting-edge in parsing technology, crafted to enable Retrieval-Augmented Generation (RAG) applications to effectively work with complex PDFs that include embedded tables and charts. This advancement opens up possibilities that were previously unattainable with existing methods. We are thrilled about the potential that LlamaParse brings to the table.
Over the last few months, our focus has been intensely fixed on a particular challenge, one that’s surprisingly common across a diverse range of data types and industries, including academic papers on ArXiv, 10-K filings, and medical reports. The standard methods of chunking and retrieving data simply don’t suffice for these complex documents. We pioneered a groundbreaking approach with our novel recursive retrieval RAG technique, which enables hierarchical indexing and querying of tables and text within documents. The remaining hurdle was mastering the parsing of tables and text, a challenge we’re now poised to overcome.
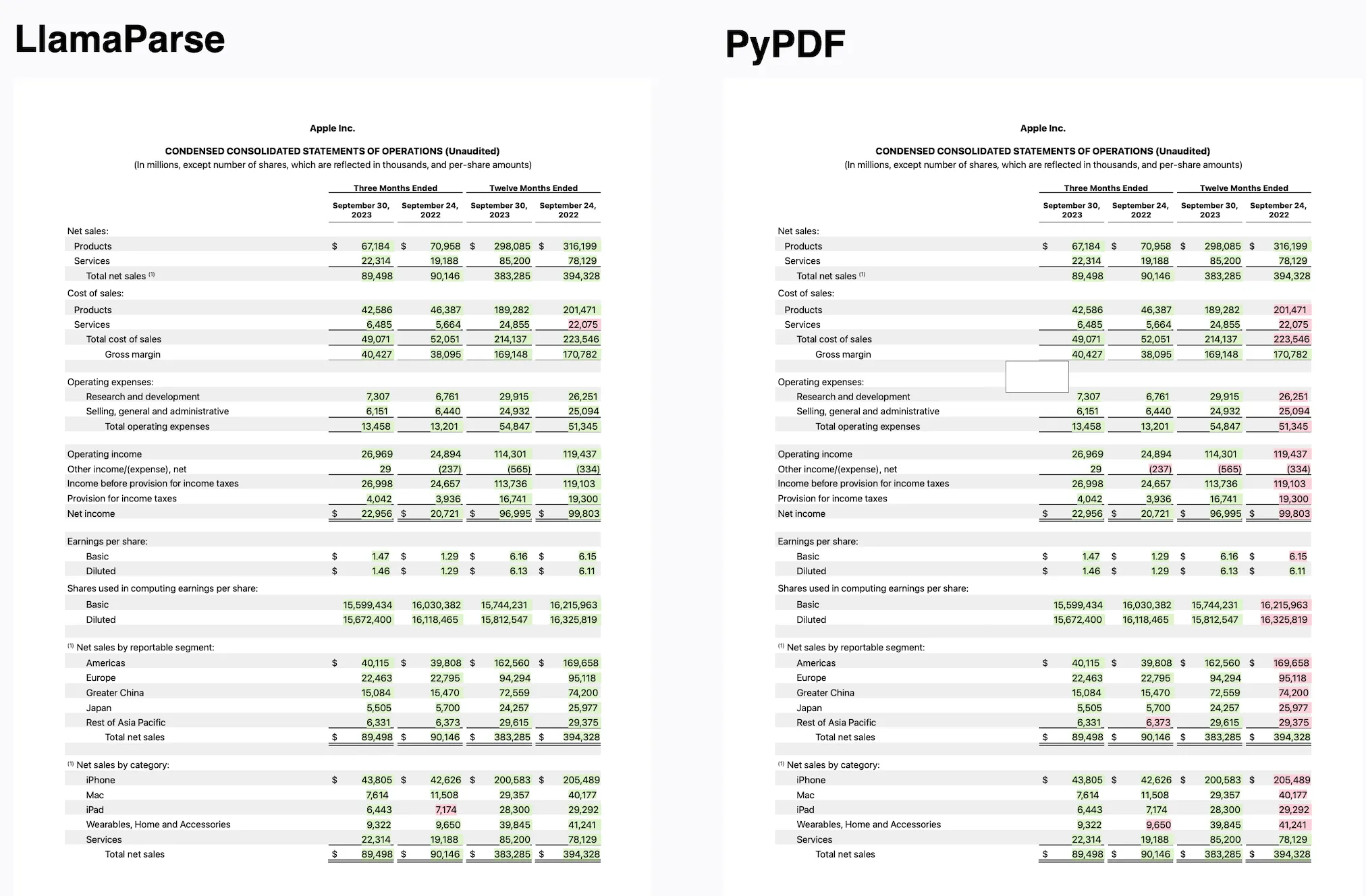
LlamaParse is our proprietary parsing service, exceptionally adept at transforming PDFs containing complex tables into a neatly organized markdown format. This format seamlessly integrates with sophisticated Markdown parsing and recursive retrieval algorithms found within our open-source library. The outcome is a capability to construct RAG over intricate documents, enabling the answering of queries across both tabular and unstructured data with unprecedented accuracy and efficiency.

How to use LlamaParse
This service is currently offered in public preview mode, making it accessible to all users with a daily usage cap of 1,000 pages. It functions as an independent service but also integrates seamlessly with our managed ingestion and retrieval API. For more information and to start using LlamaParse, refer to our onboarding guide. Here’s a quick example of how to use LlamaParse in your project:
from llama_parse import LlamaParse
# Initialize the LlamaParse parser with your API key and desired output format
parser = LlamaParse(
api_key="llx-...", # This can also be set as an environment variable named LLAMA_CLOUD_API_KEY
result_type="markdown", # Choose between "markdown" and "text" output formats
verbose=True # Enables detailed logging for debugging purposes
)This snippet demonstrates the simplicity of integrating LlamaParse into your workflow, offering a straightforward way to parse complex PDFs into structured markdown or plain text.
Next Steps
Based on valuable input from our early adopters, we’re actively expanding LlamaParse’s capabilities beyond its current focus on PDFs with tables. Our roadmap includes enhancing support for figures and broadening compatibility with a wider array of prevalent document formats, such as .docx (Word documents), .pptx (PowerPoint presentations), and .html (web pages).
This evolution will ensure users have a comprehensive tool for parsing and extracting information from a diverse range of complex documents, further streamlining the process of building sophisticated RAG systems capable of handling both structured and unstructured data.
By Jerry Liu, co-founder/CEO @llama_index
Read related articles: