Instead of doing naive text splitting, extract a document knowledge graph to power your advanced RAG pipeline. This tutorial by Fanghua Yu shows you a novel use case of LlamaParse – extract it into structured markdown that you can then convert into a document graph that you can store in a graph db “neo4j”.
Once there, you have the option of not only doing top-k vector search, but the plethora of query options available in Graph RAG: text-to-cypher, vector search + keyword search + traversing knowledge links, and more. All of these are available in llamaindex
Introduction
Last month, LlamaIndex unveiled LlamaCloud, a cutting-edge managed service designed to enhance parsing, ingestion, and retrieval processes for use in production-level context-augmentation, particularly for LLM (Large Language Models) and RAG (Retrieval-Augmented Generation) applications.
LlamaCloud’s core offerings include LlamaParse, an advanced proprietary parsing tool adept at handling complex documents containing embedded elements such as tables and figures. This tool is fully integrated with LlamaIndex’s ingestion and retrieval systems, making it possible to develop retrieval systems capable of navigating complex, semi-structured documents. This integration is crucial for addressing intricate questions that were previously challenging to manage.
Additionally, LlamaCloud introduces a Managed Ingestion and Retrieval API that simplifies the processes of loading, processing, and storing data specifically for RAG applications.
Previously, I’ve discussed how document parsing pipelines can be utilized to extract comprehensive content (beyond mere text) from documents to construct knowledge graphs that enhance the accuracy and efficacy of RAG applications. In this article, I will provide a step-by-step guide on how to integrate LlamaParse with Neo4j to achieve these goals.
High-Level Process Overview: Creating a Document Processing Pipeline with LlamaParse and Neo4j
The development of a document processing pipeline using LlamaParse and Neo4j involves several crucial steps:
- Setting Up the Environment: This step includes detailed instructions on configuring your Python environment, ensuring the necessary libraries and tools like LlamaParse and the Neo4j database driver are installed and ready to use.
- PDF Document Processing: This phase demonstrates the use of LlamaParse for reading PDF documents. It covers how to extract important elements such as text, tables, and images from the documents and convert this information into a structured format that is suitable for database insertion.
- Designing the Graph Model: Provides guidance on how to design a graph model that effectively represents the entities and relationships extracted from your PDF documents. This model will facilitate efficient querying and analysis.
- Storing Extracted Data in Neo4j: Includes comprehensive code examples that show how to establish a connection to a Neo4j database from Python, how to create nodes and relationships based on the extracted data, and how to use Cypher queries to populate the database.
- Generating and Storing Text Embeddings: Explains the process of generating text embeddings using a previously created program that calls the OpenAI API, and how to store these embeddings as vectors in Neo4j for advanced querying capabilities.
- Querying and Analyzing Data: Offers examples of Cypher queries that can be used to retrieve and analyze the stored data, demonstrating how Neo4j can be utilized to discover insights and relationships within your PDF content.
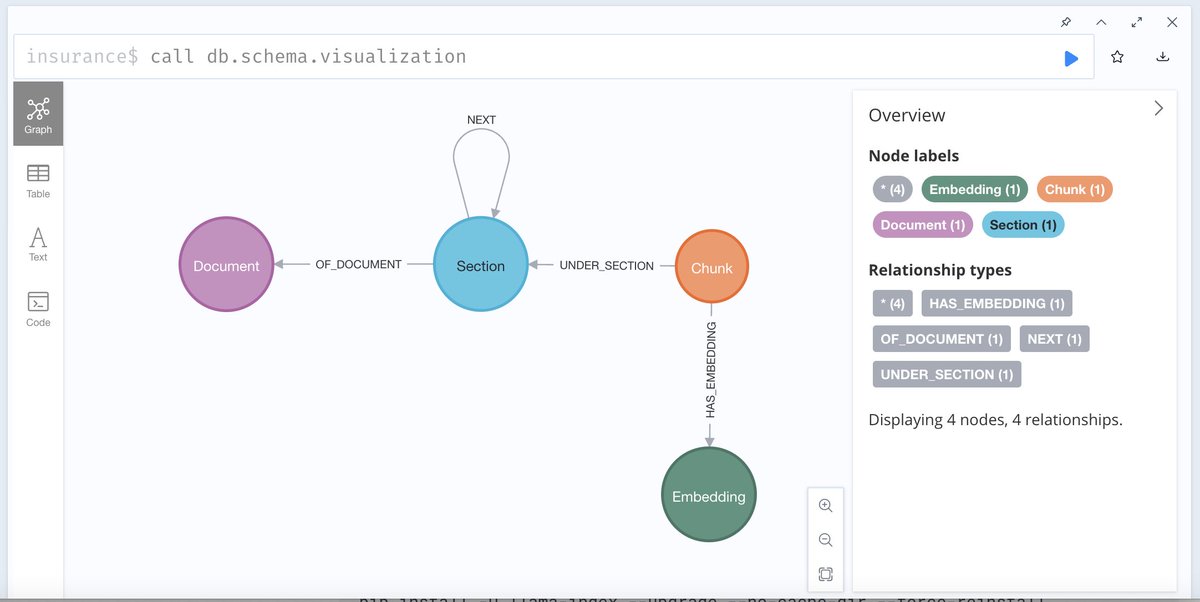
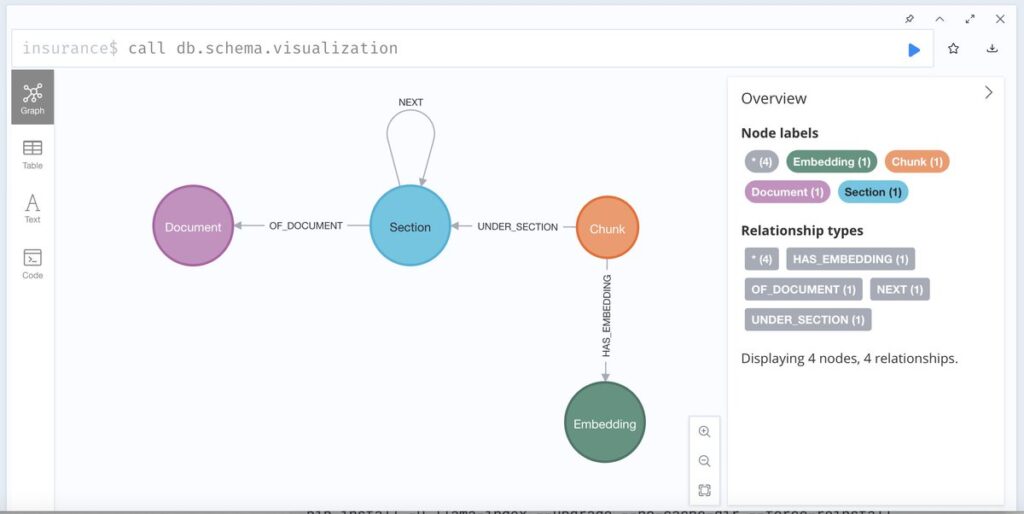
Graph model for parsed document
No matter which PDF parsing tool is utilized, the graph schema for storing results in Neo4j as a knowledge graph remains notably straightforward and consistent.
Parsing PDF Documents with LlamaParse
To parse PDF documents using the newly introduced LlamaParse PDF reader, follow these two straightforward steps:
- Index Building and Query Generation: Utilize the raw Markdown text extracted from the PDF as nodes to construct an index. Apply a simple query engine to generate the results.
- Recursive Query Engine Construction: Use the MarkdownElementNodeParser to parse the Markdown output generated by LlamaParse. This parser aids in building a recursive retriever query engine for result generation.
Storing Extracted Content in Neo4j
Here’s an example of how to implement this process using Python:
from llama_parse import LlamaParse
from llama_index.core.node_parser import MarkdownElementNodeParser
# Specify the PDF file to be parsed
pdf_file_name = './insurance.pdf'
# Load the data from the PDF using LlamaParse configured for Markdown output
documents = LlamaParse(result_type="markdown").load_data(pdf_file_name)
# Initialize the MarkdownElementNodeParser with required configurations
node_parser = MarkdownElementNodeParser(llm=llm, num_workers=8)
# Use the parser to extract nodes (text) and objects (tables) from the documents
nodes = node_parser.get_nodes_from_documents(documents)
base_nodes, objects = node_parser.get_nodes_and_objects(nodes)This code snippet outlines the process of loading a PDF, parsing its contents using Markdown format, and extracting both textual and non-textual data elements for further processing and storage in a Neo4j database.
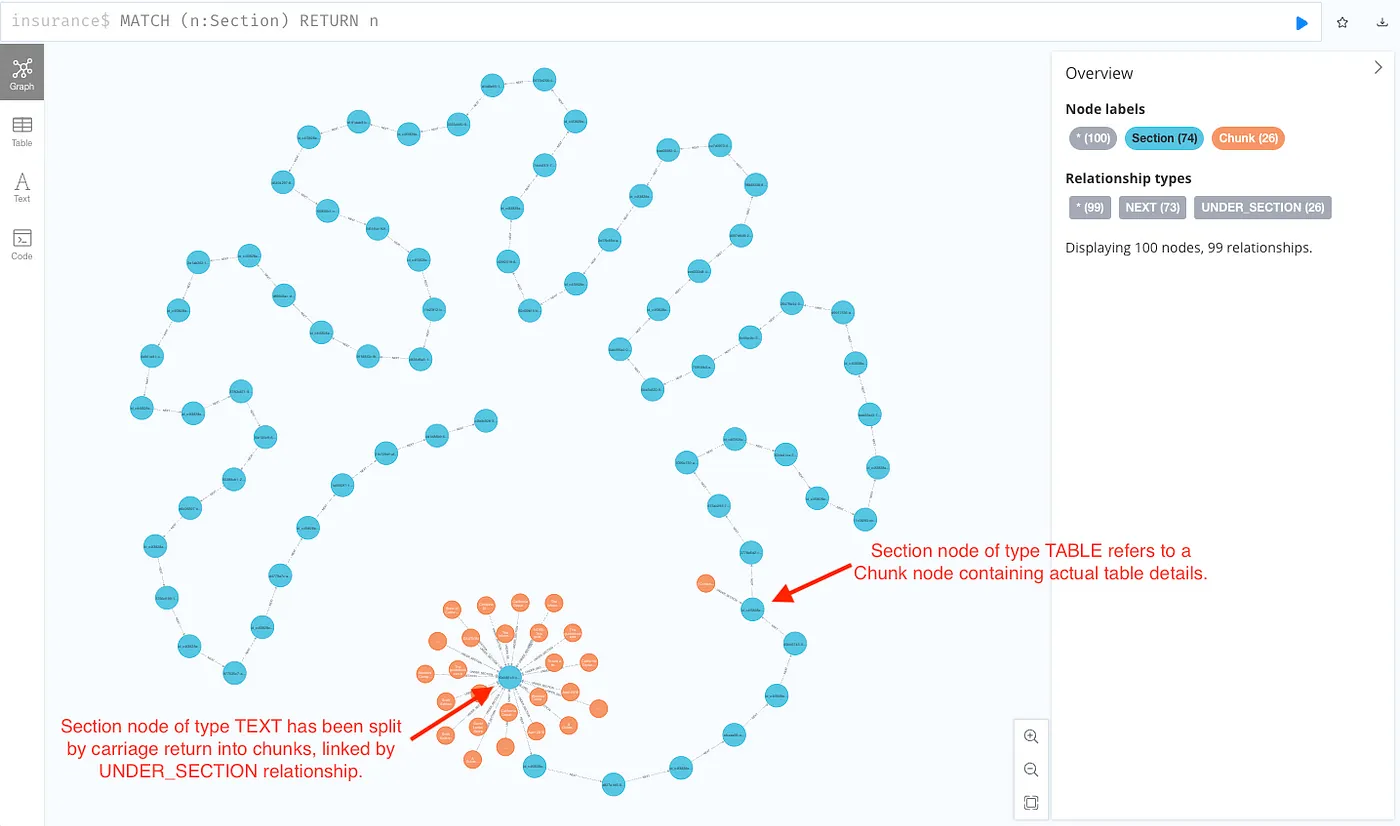
Querying Document Graph
Below is how a document looks like after it is ingested into Neo4j.
Conclusions
LlamaParse distinguishes itself as an exceptionally proficient tool for parsing PDF documents. It excels in handling the intricate details of both structured and unstructured data with notable efficiency. Thanks to its sophisticated algorithms and user-friendly API, LlamaParse enables the smooth extraction of text, tables, images, and metadata from PDFs. This capability effectively simplifies what is typically a complex and demanding task, making the process much more manageable and streamlined.
Storing the extracted data in Neo4j as a graph further enhances the advantages of using LlamaParse. By representing data entities and their relationships within a graph database, users gain the ability to uncover patterns and connections that might be challenging or even impossible to detect using traditional relational databases. Neo4j’s graph model provides a natural and intuitive method for visualizing complex relationships, thereby improving the capacity for sophisticated analysis and the generation of actionable insights.
Moreover, employing a consistent document knowledge graph schema greatly facilitates integration with other tools for downstream tasks. For example, it simplifies the process of building Retrieval Augmented Generation applications using the GenAI Stack, which includes technologies like LangChain and Streamlit. This integration not only streamlines workflows but also enhances the overall functionality and efficiency of data-driven projects.
Read related articles: