
The Mistral AI team has unveiled the Mistral 7B, touted as the most potent language model of its size currently available. Mistral 7B is a model with 7.3B parameters. Let’s compare it with LLama LLM.
Its capabilities include:
- Surpassing the performance of Llama 2 13B across all benchmarks.
- Exceeding the results of Llama 1 34B in numerous benchmarks.
- Nearing the CodeLlama 7B’s performance in coding tasks while maintaining proficiency in English tasks.
- Incorporating Grouped-query attention (GQA) for swifter inference.
- Utilizing Sliding Window Attention (SWA) to manage longer sequences more cost-effectively. The Mistral AI team has made Mistral 7B available under the Apache 2.0 license, ensuring unrestricted use.
Users can:
- Download and operate it anywhere, including locally, through the team’s reference implementation.
- Launch it on any cloud platform like AWS, GCP, or Azure using the vLLM inference server and skypilot.
- Access it via HuggingFace.
Fine-tuning Mistral 7B is straightforward for any task. As evidence, the Mistral AI team offers a chat model version that surpasses the Llama 2 13B chat.
Detailed Performance Analysis
The Mistral AI team conducted a comparison of Mistral 7B with the Llama 2 series, ensuring all model evaluations were redone for an unbiased comparison.
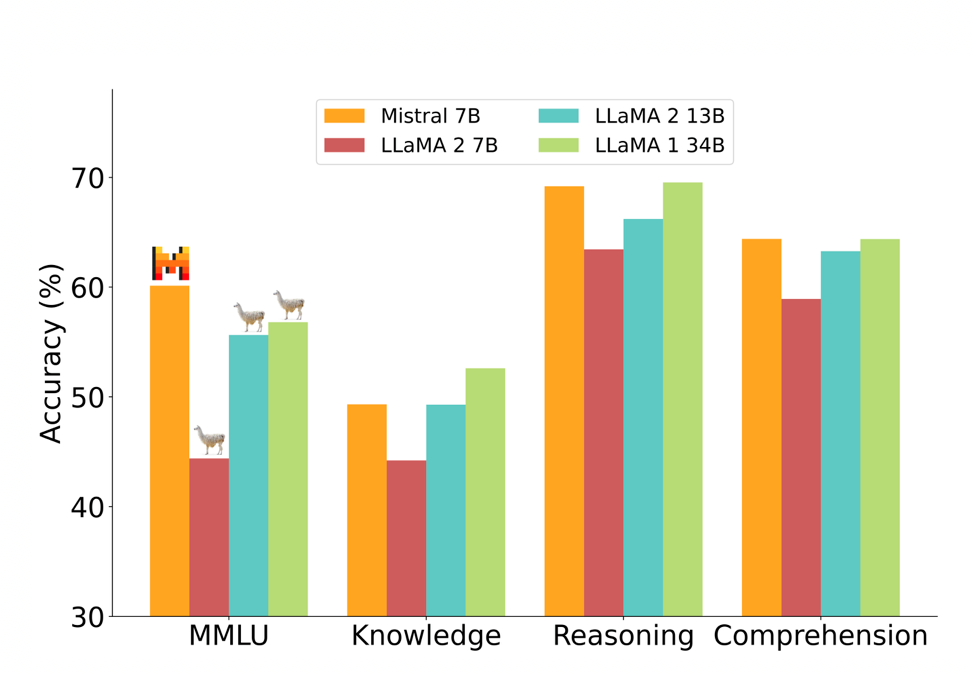
The performance metrics of Mistral 7B and various Llama models across a broad spectrum of benchmarks were presented. Every model underwent re-evaluation using the team’s evaluation pipeline to ensure precise comparisons. Mistral 7B notably surpasses Llama 2 13B in all metrics and matches the performance of Llama 34B. It also excels in code and reasoning benchmarks.
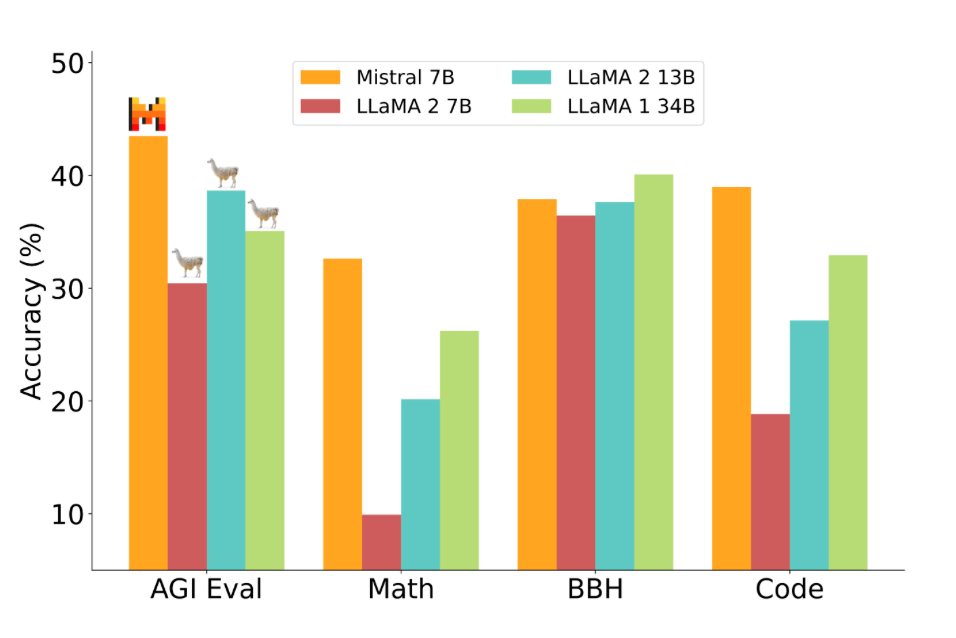
The benchmarks were grouped by themes:
- Commonsense Reasoning
- World Knowledge
- Reading Comprehension
- Math
- Code
- Popular aggregated results
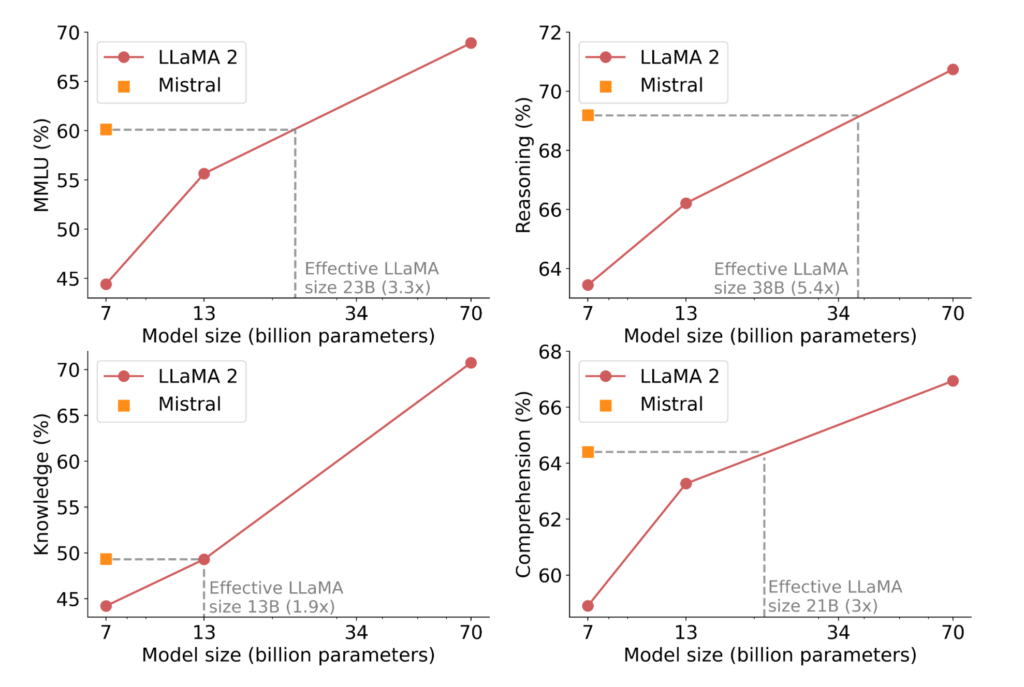
A notable metric for comparing models in the cost/performance domain is the “equivalent model sizes.” In reasoning, comprehension, and STEM reasoning (MMLU), Mistral 7B’s performance is akin to a Llama 2 model three times its size, resulting in memory savings and increased throughput.
Fine-tuning Mistral 7B for Chat
To highlight Mistral 7B’s adaptability, the Mistral AI team fine-tuned it using publicly available instruction datasets on HuggingFace, without any special techniques or exclusive data. The resultant model, named Mistral 7B Instruct, surpasses all other 7B models on MT-Bench and is comparable to 13B chat models.
MT-Bench
The Mistral 7B Instruct model serves as a testament to the base model’s fine-tuning potential. The Mistral AI team eagerly anticipates collaborating with the community to refine the models, ensuring they adhere to guardrails, making them suitable for deployment in environments that demand moderated outputs.
Read related articles: