Blog
-
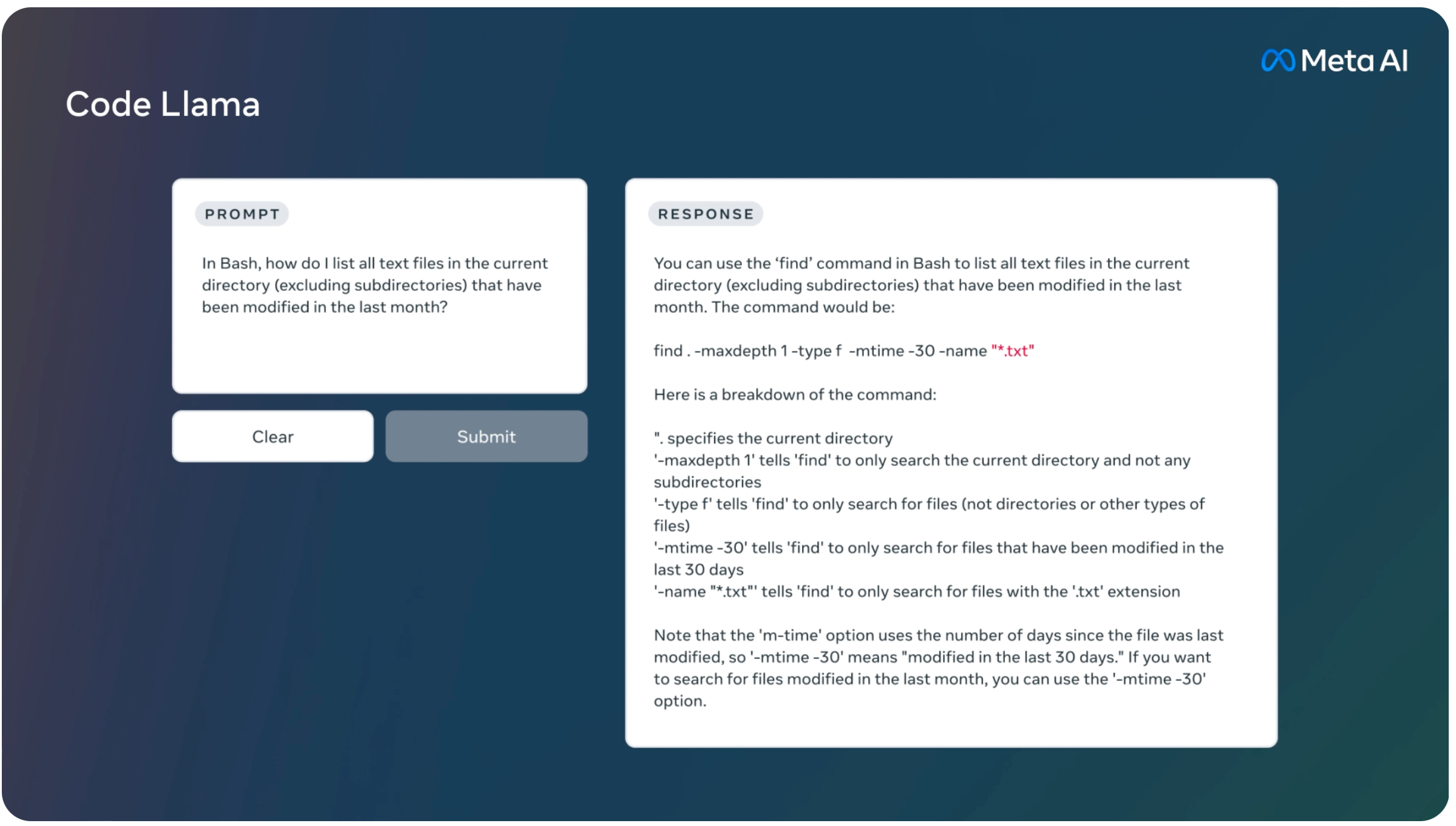
Code Llama: Open Foundation Models for Code
Meta release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. Meta provide multiple flavors to cover a wide range of applications: foundation models (Code Llama), Python specializations (Code Llama – Python),…
-

Llama 2 Model Details
Meta developed and publicly released the Llama 2 family of large language models (LLMs), a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. The fine-tuned LLMs, called Llama-2-Chat, are optimized for dialogue use cases. Llama-2-Chat models outperform open-source chat models on most benchmarks we tested,…
-

Why LLama 2 Matters
In the study detailing the creation of Llama 2, the researchers evaluated its performance against various benchmarks, juxtaposing it with both open and closed source models such as GPT-3.5, GPT-4, PaLM, and PaLM 2. Briefly, Llama’s 70B versions surpassed other open source LLMs in performance. They matched the capabilities of GPT-3.5 and PaLM on many…
-

LLama 2 vs GPT-4
In the experiment conducted by Anyscale, it was discovered that Llama-2-70b is nearly as proficient in factuality as GPT-4 and significantly superior to GPT-3.5-turbo. Anyscale employed their Endpoints to juxtapose Llama 2 7b, 13b, and 70b (chat-hf fine-tuned) against OpenAI’s GPT-3.5-turbo and GPT-4. They utilized a triply-verified, hand-labeled dataset of 373 news report statements, presenting…
-

Anyscale incorporates Llama-2
Anyscale incorporates Llama-2 into their ecosystem. The company just announced a collaboration with Meta to strengthen the Llama-2 model. Joe Spisak, from Meta, will provide more insights at the Ray Summit. About Llama and The Llama Ecosystem Llama, especially Llama-2, is a series of LLMs released to the public by Meta. They vary in size…
-

Llama 2 on Vertex AI
Vertex AI has broadened its generative AI development capabilities with the introduction of new models. These models, now available in their Model Garden, further underline their commitment to cater to their customers by providing diverse options within an open ecosystem. Among the new additions are Llama 2 and Code Llama from Meta, as well as…
-

Yarn Llama 2
Yarn Llama 2 has been trained and released on HuggingFace. This language model trained for 128k context. To ensure this model functions as intended, the Flash Attention library is necessary. Refer to the Model Usage segment for guidance on installation. Team Contributors bloc97: Role – Methods, Publication, and Evaluations @theemozilla: Role – Methods, Publication, and…
-

Run Llama-2
Meta has unveiled Llama 2, a model trained on a massive 2 trillion tokens with a default context length of 4096. The Llama 2-Chat models, specifically fine-tuned using over a million human annotations, are optimized for chat applications. In this article we will explain ho to Run Llama-2 locally using Ollama. Training for Llama 2…
-

LlamaIndex
LLMs essentially serve as a bridge, providing a natural language interface between humans and the vast expanse of inferred data. Most of these models, accessible to the masses, have their foundation built upon copious amounts of public data sources – from the likes of Wikipedia and email threads to academic textbooks and intricate source codes.…