Meta just released Llama Code, a large language model (LLM) capable of using text prompts to generate code. Llama Code stands at the forefront of publicly available LLMs for coding tasks and offers the promise of accelerating workflows for existing developers. Additionally, it can lower the hurdle for newcomers learning to code.
There is potential for Code Llama to serve both as a productivity enhancer and an educational asset, assisting programmers in creating more robust, thoroughly documented software.
The generative AI domain is witnessing swift transformations. Meta believes that an open approach to the current AI landscape paves the way for the creation of AI tools that are cutting-edge, secure, and conscientious. They have made Code Llama available under the same community license as Llama 2.
How Llama Code Works
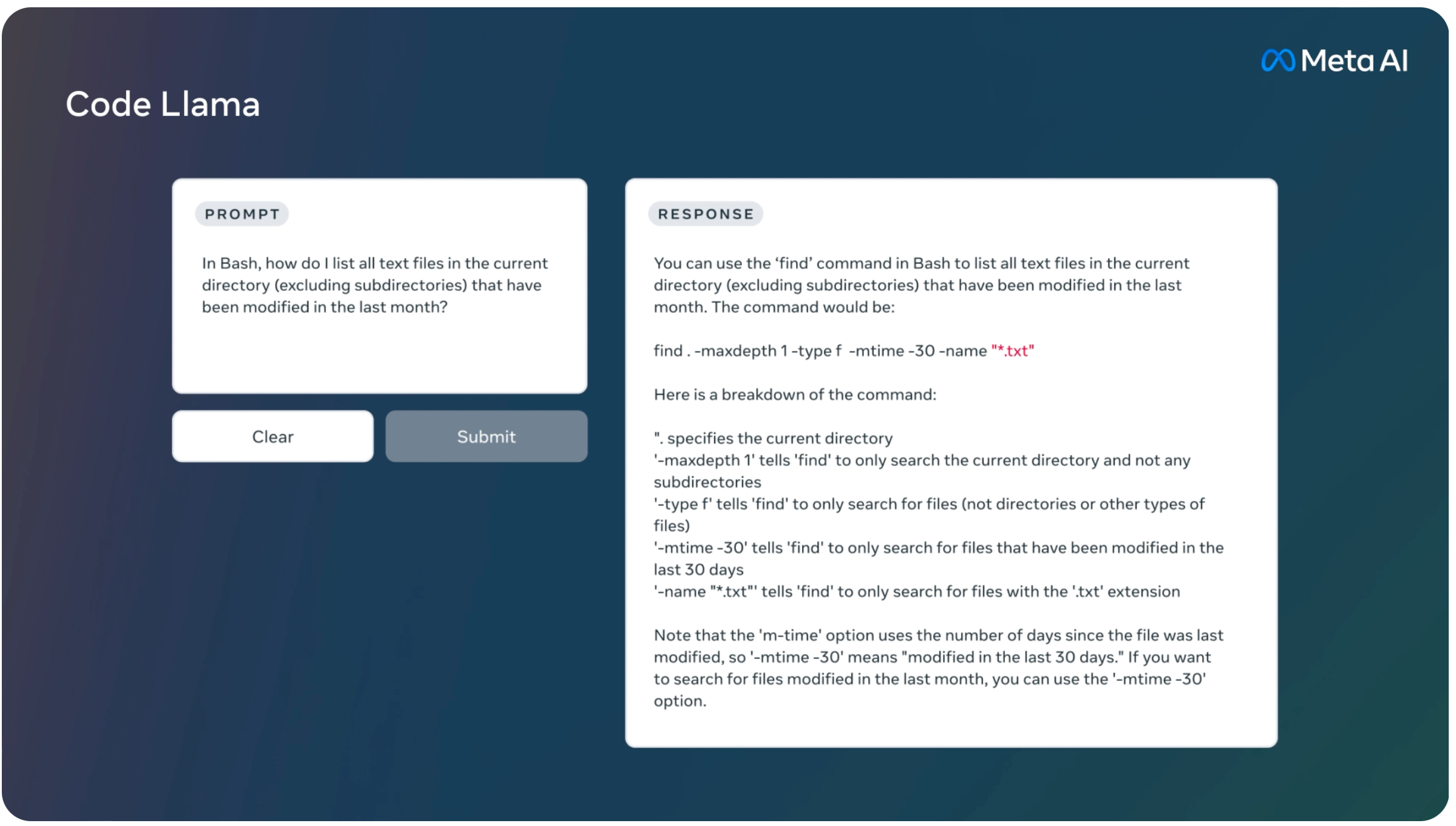
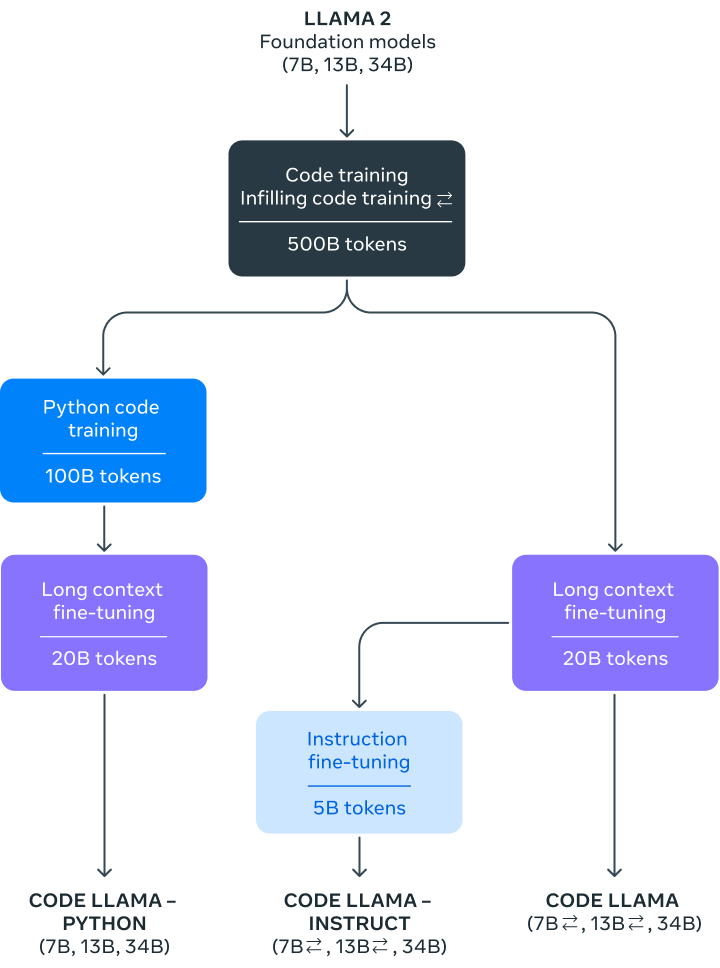
Llama Code is a coding-focused adaptation of Llama 2, evolved by extending Llama 2’s training on its distinct coding datasets and drawing more extensively from the same dataset. In essence, the model boasts augmented coding proficiencies, grounded on the foundation of Llama 2. It’s capable of producing code, and narratives about code, from both code-based and everyday language prompts (for instance, “Craft a function that delivers the Fibonacci sequence.”). It’s also handy for code auto-completion and troubleshooting. It acknowledges numerous dominant languages in current use, like Python, C++, Java, PHP, Typescript (Javascript), C#, and Bash.
Meta is introducing three variants of Llama Code, featuring 7B, 13B, and 34B parameters respectively. Meta educated every model using 500B tokens of coding and coding-associated information. The 7B and 13B foundational and instructional models also possess the fill-in-the-middle (FIM) function, empowering them to embed code within pre-existing code. This implies they are ready to assist in endeavors such as instantaneous code completion.
Each of these three models caters to distinct serviceability and response-time needs. For instance, the 7B variant can be operated using a single GPU. Although the 34B model delivers superior outcomes and offers enhanced coding assistance, the compact 7B and 13B versions are swifter, more apt for missions demanding rapid response, like instantaneous code completion.
You can read more about Llama 2 model sizes (7B, 13B, 70B).
The Llama Code variants can reliably produce content given up to 100,000 tokens of context. All are cultivated on sequences of 16,000 tokens, showcasing advancements when interacting with inputs up to 100,000 tokens.
Beyond merely enabling the creation of extensive programs, these elongated input sequences open the door to novel applications for a coding LLM. Users, for example, can supply the model with broader context from their programming framework to make the output more pertinent. This proves valuable in debugging situations within extensive programming frameworks, where comprehending every piece of code relevant to a specific issue might be daunting for programmers. In scenarios where developers need to debug extensive code segments, they can introduce the entire span of the code to the model.
Fine-tuned Code Llama
Moreover, Meta fine-tuned two more versions: “Llama Code – Python” and “Llama Code – Instruct”.
Llama Code – Python
Llama Code – Python is a dialect-specific derivative of Llama, honed further on 100B tokens of Python code. As Python stands as the most evaluated language for code creation – and given Python and PyTorch‘s significance in the AI sphere – we’re convinced that a dedicated model offers extra value.
Llama Code – Instruct
Llama Code – Instruct is a direction-optimized and harmonized form of Llama. Directional tuning persists in the training trajectory but follows an alternate goal. The model receives a “plain language directive” as input along with the anticipated outcome. This refines its capability to discern human expectations from their cues. We suggest the Llama Code – Instruct variants when employing the model for code synthesis, as it’s designed to produce constructive and secure responses in plain language.
Meta advise against using Llama Code or Llama Code – Python for standard linguistic assignments since neither is tailored to heed ordinary language directions. Llama Code is primed for coding-specific endeavors and isn’t fitting as a primary model for alternative activities.
When operating the Llama Code models, users are obliged to respect Meta’s licensing and permissible usage guidelines.
Evaluating Performance
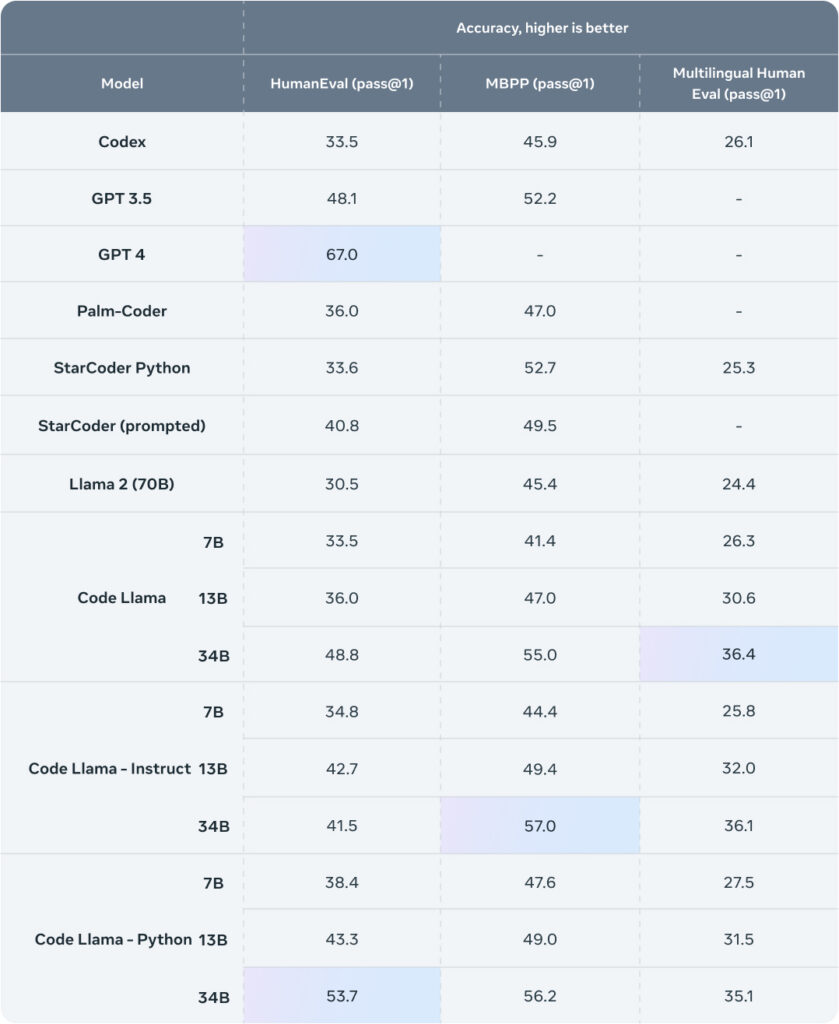
To scrutinize Llama Code’s efficacy in comparison to current offerings, Meta utilized two renowned coding metrics: HumanEval and Mostly Basic Python Programming (MBPP). HumanEval evaluates the model’s prowess in finalizing code derived from docstrings, while MBPP examines its capability to script code from a given narrative.
The metrics from our benchmarking revealed that Llama Code excelled beyond open-source, code-centric LLMs and surpassed Llama 2. Specifically, Llama Code 34B registered scores of 53.7% on HumanEval and 56.2% on MBPP. These results not only towered over other cutting-edge open alternatives but also equaled the performance of ChatGPT.
Like all avant-garde technologies, Code Llama carries inherent risks. Ensuring the responsible construction of AI models is paramount, prompting us to incorporate numerous safeguards prior to Llama Code’s launch. During proactive defense assessments, Meta’s engineers undertook a systematic analysis of Llama Code’s propensity to produce harmful code. They formulated prompts explicitly designed to elicit harmful code and gauged Llama Code’s replies against those from ChatGPT (GPT3.5 Turbo). Meta’s findings indicated that the Code model provided more secure responses.
For a comprehensive overview of our defense-oriented evaluations, expert insights from professionals in responsible AI, aggressive security protocols, malware creation, and software development can be found in our scholarly article.
Releasing Llama
Developers are increasingly turning to LLMs for support in tasks as diverse as crafting new software to troubleshooting pre-existing code. The objective is to streamline developer processes, enabling them to center their attention on the more human-oriented facets.
Meta devs are of the conviction that LLMs tailored for coding are especially potent when developed with transparency in mind. This approach fosters both innovation and security. Making code-centric models accessible to the public can pave the way for the emergence of groundbreaking tech. By unveiling models like Llama Code, the broader community has the chance to assess its strengths, and rectify any vulnerabilities.
The procedures followed during Llama Code’s training can be accessed on Github repository.
The model’s weights are also obtainable.
Read more related topics: