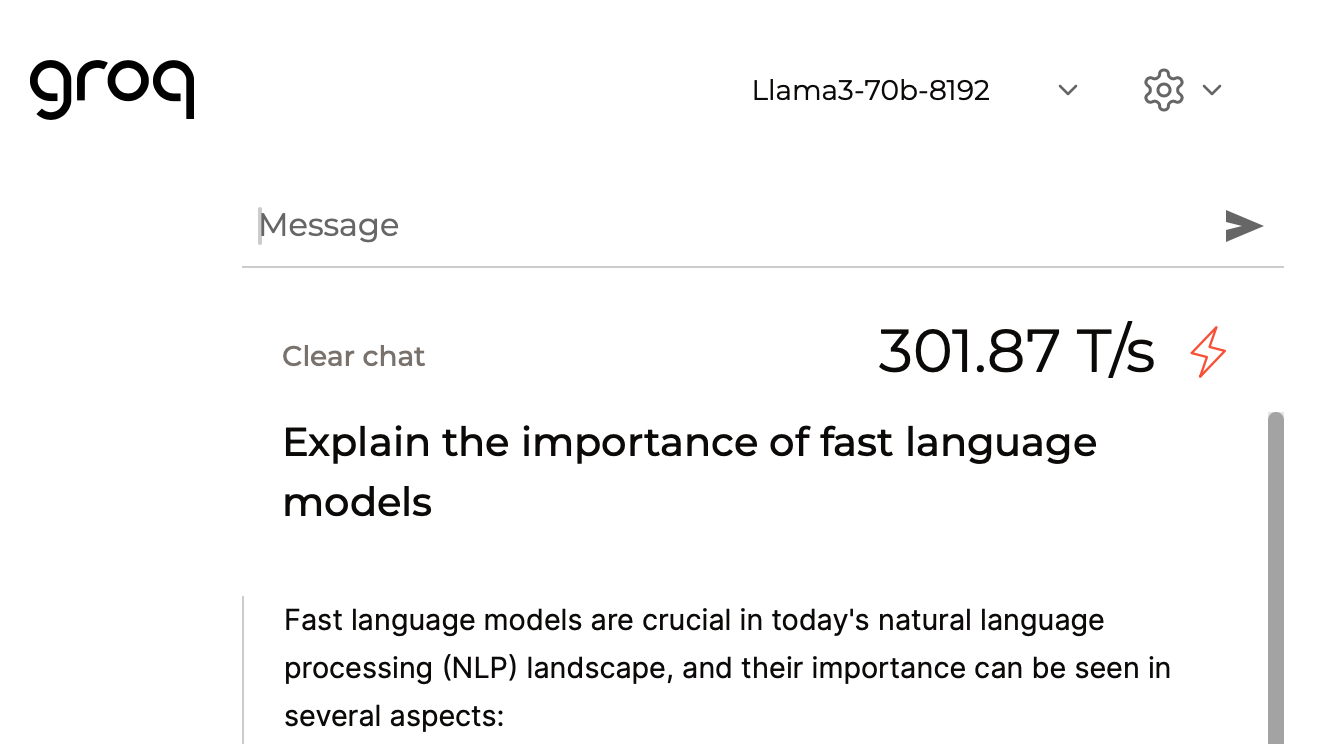
Okay, so this is the actual speed of generation, and we’re achieving more than 800 tokens per second, which is unprecedented. Since the release of LLama 3 earlier this morning, numerous companies have begun integrating this technology into their platforms. One particularly exciting development is its integration with Groq Cloud, which boasts the fastest inference speed currently available on the market.

Groq has seamlessly incorporated LLama 3 into both their playground and the API, making both the 70 billion and 8 billion parameter versions available. I’ll discuss how to get started with both versions in the playground and via the API if you’re building your own applications on top of it.
Using LLama 3 with Groq
To begin, let’s select the LLama 3 models, starting with the 70 billion parameter model.
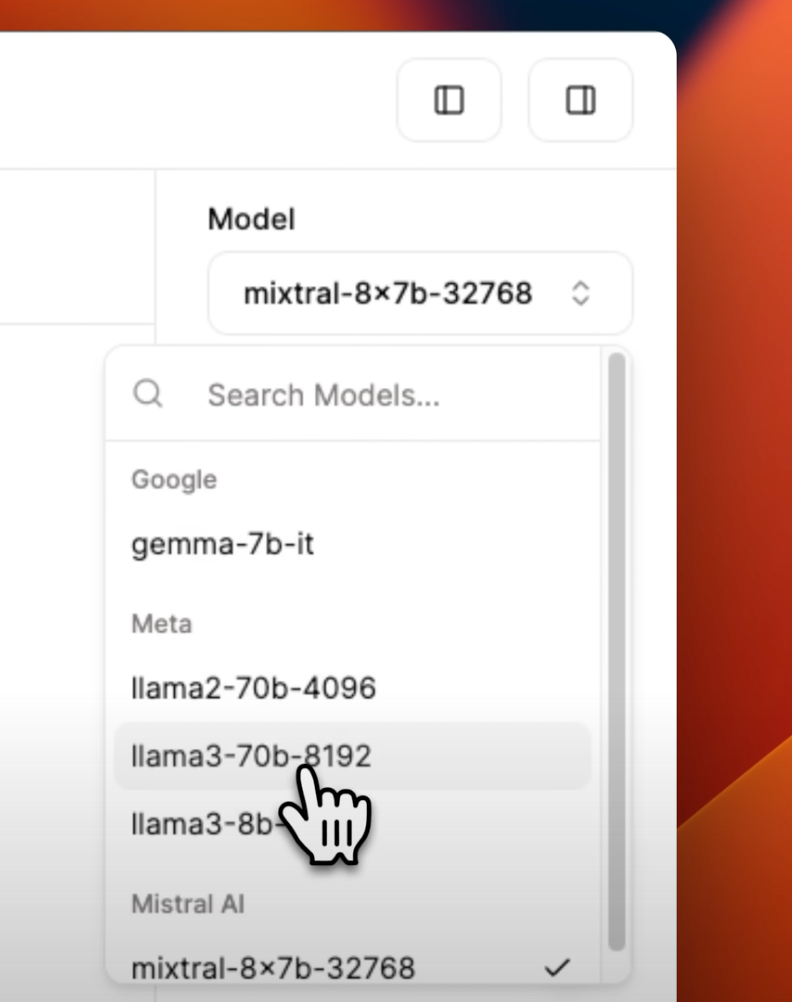
I’ll use a test prompt to illustrate the response capabilities without focusing on the content accuracy; instead, we’ll concentrate on the speed of inference. The prompt I’ll use is:
“I have a flask for 2 gallons and one for 4 gallons. How do I measure six gallons?”
This prompt likely appeared in its training data, showcasing the rapid inference capabilities.
Here’s the speed of inference which was impressively fast; it took about half a second, and the speed of generation was around 300 tokens per second.
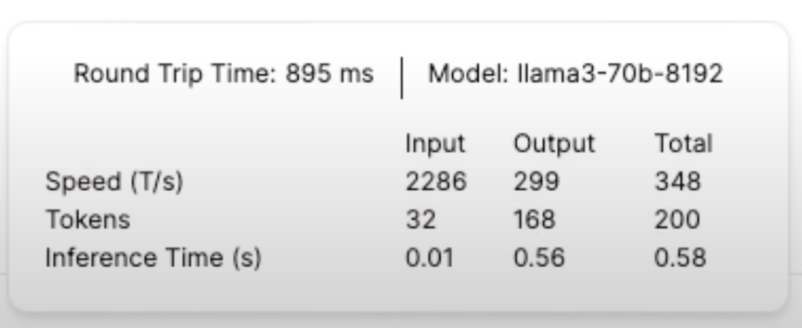
Now, let’s test the same prompt on the 8 billion model. This time, the generation reached about 800 tokens per second and it took just a fraction of a second.
Extended Applications and Performance
Next, let’s explore what happens when we ask it to generate longer text. As the model generates longer content, it’s expected to take more time, but let’s see if it has any impact on the number of tokens per second.
Here, I asked it to write a 500-word essay on the importance of Open Source AI models. First using the 8 billion model, and the number of tokens per second was pretty consistent, which is quite impressive. Next, we’ll look at the 70 billion model and after this, I’ll guide you through using the API.

This was real-time speed. It’s definitely not 5,000 words but probably somewhere around a couple of thousand words. However, the speed of generation remained pretty consistent, which is fantastic. You can also include a system message if you wish.
Typically, you’d use the playground to test the model as well as the prompts and once you’re satisfied with that and you want to integrate it into your own applications, then you move on to using the Groq API.
Setting Up and Using the Groq API
To demonstrate, I’ve put together a tutorial using a Google notebook to show you how to integrate Groq in your applications through the Groq API. First, we install the Python client using
pip install Groq.
Next, we need to generate our own API key by going to the playground, clicking on API Keys, then creating a new API key.
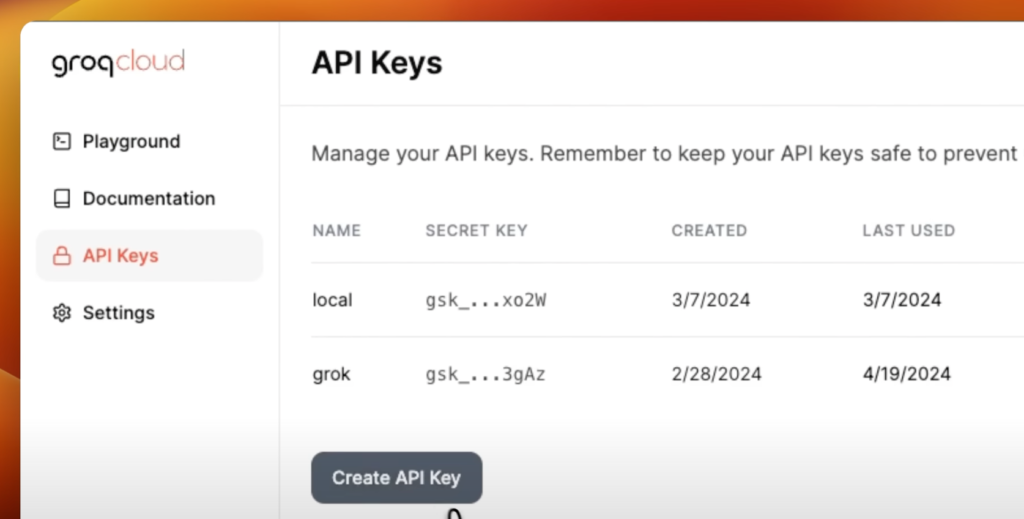
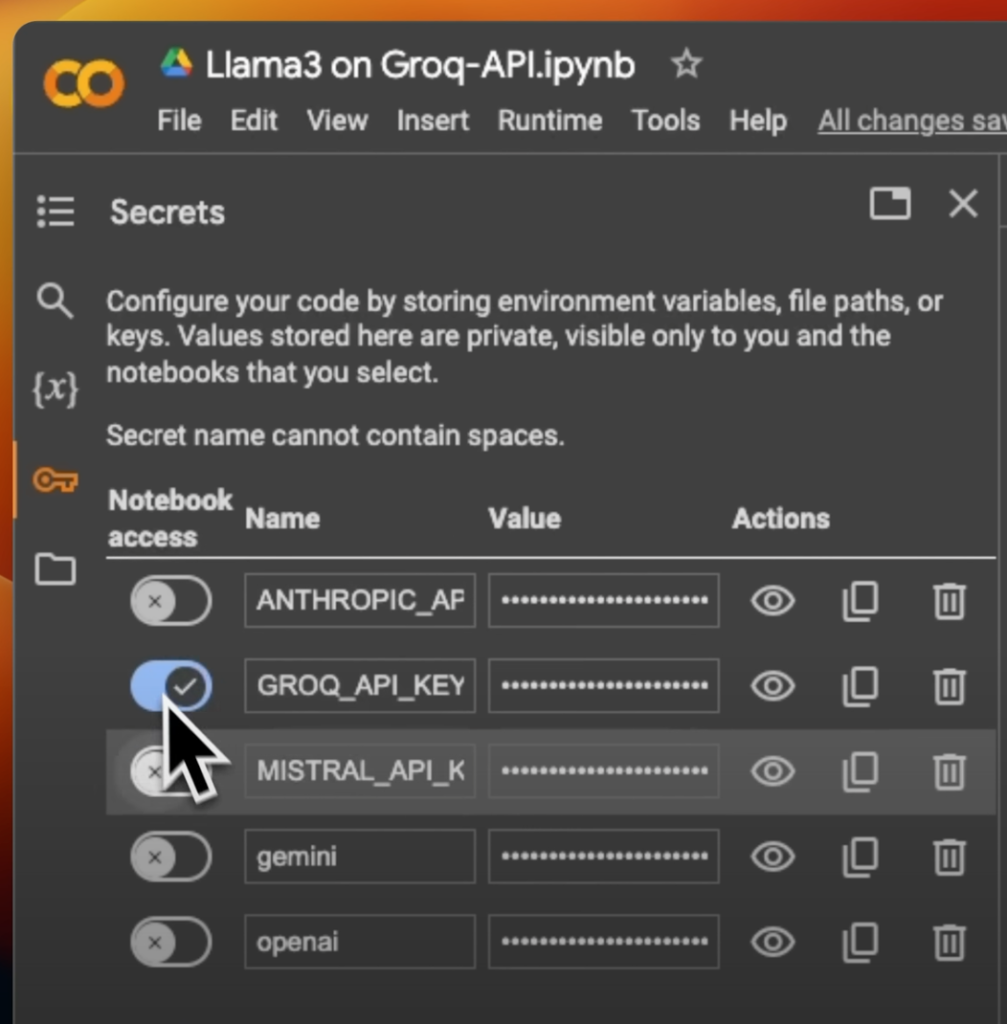
I have existing API keys, so I’ll be using those. Since I’m using Google Colab, I’ve put my API key as a secret here and enabled access to this notebook.
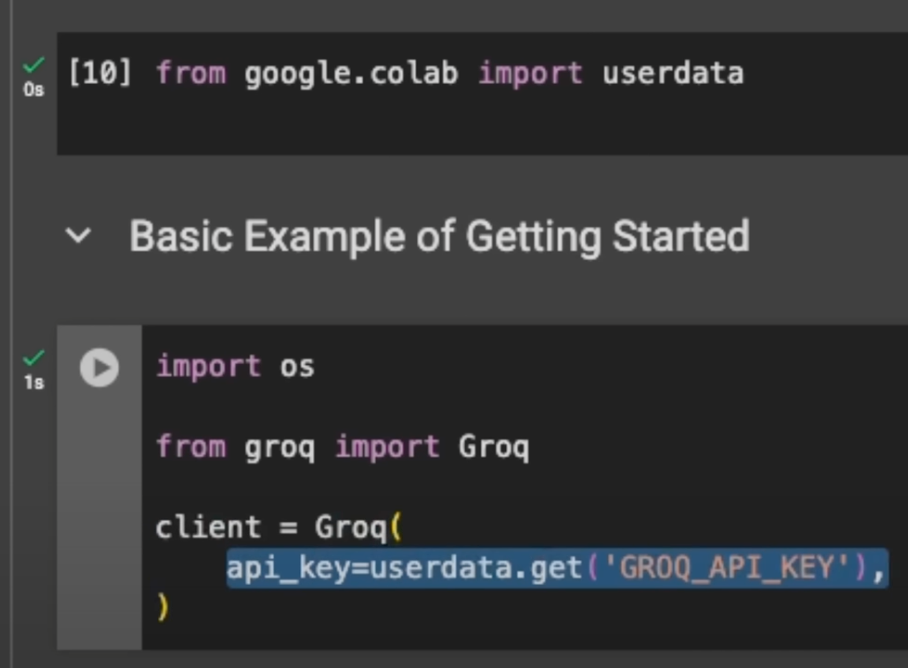
We need to import the Groq client and create it using this function, providing our API key. I’m reading it directly from the secrets within the Google Colab API client.
Now, let’s see how we perform inference. It’s pretty straightforward. We’re going to be using the chart completion endpoint. Here, we create a new message where the user asks a question, and the prompt is to explain the importance of low latency language models in the voice of Jon Snow.

Advanced Features and Future Prospects
Furthermore, you can also pass some extra parameters, such as setting the temperature, which controls the creativity or the selection of different tokens. These are optional parameters. With that system role, here’s the actual speed of generation again—this is pretty fast. Streaming is also possible here, which allows you to receive text in chunks, enhancing the responsiveness.
Both the playground and the API are currently available for free, though a paid version might be introduced soon. Since it’s free, there are rate limits on the number of tokens it can generate, so be sure to check this.
I’ll be creating a lot more content both around LLama 3 as well as Groq. Groq is also working on integrating support for Whisper, which, when implemented, will open up the new possibilities.
LLama 3 on Poe
Groq-powered inference for Llama 3 is now available on Poe! You can use Llama-3-70b-Groq and experience the state-of-the-art open source model with near-instant streaming.
Both https://poe.com/Llama-3-70b-Groq and https://poe.com/Llama-3-8b-Groq are available across the Poe iOS, Android, Mac, and Windows apps.
Read related articles: