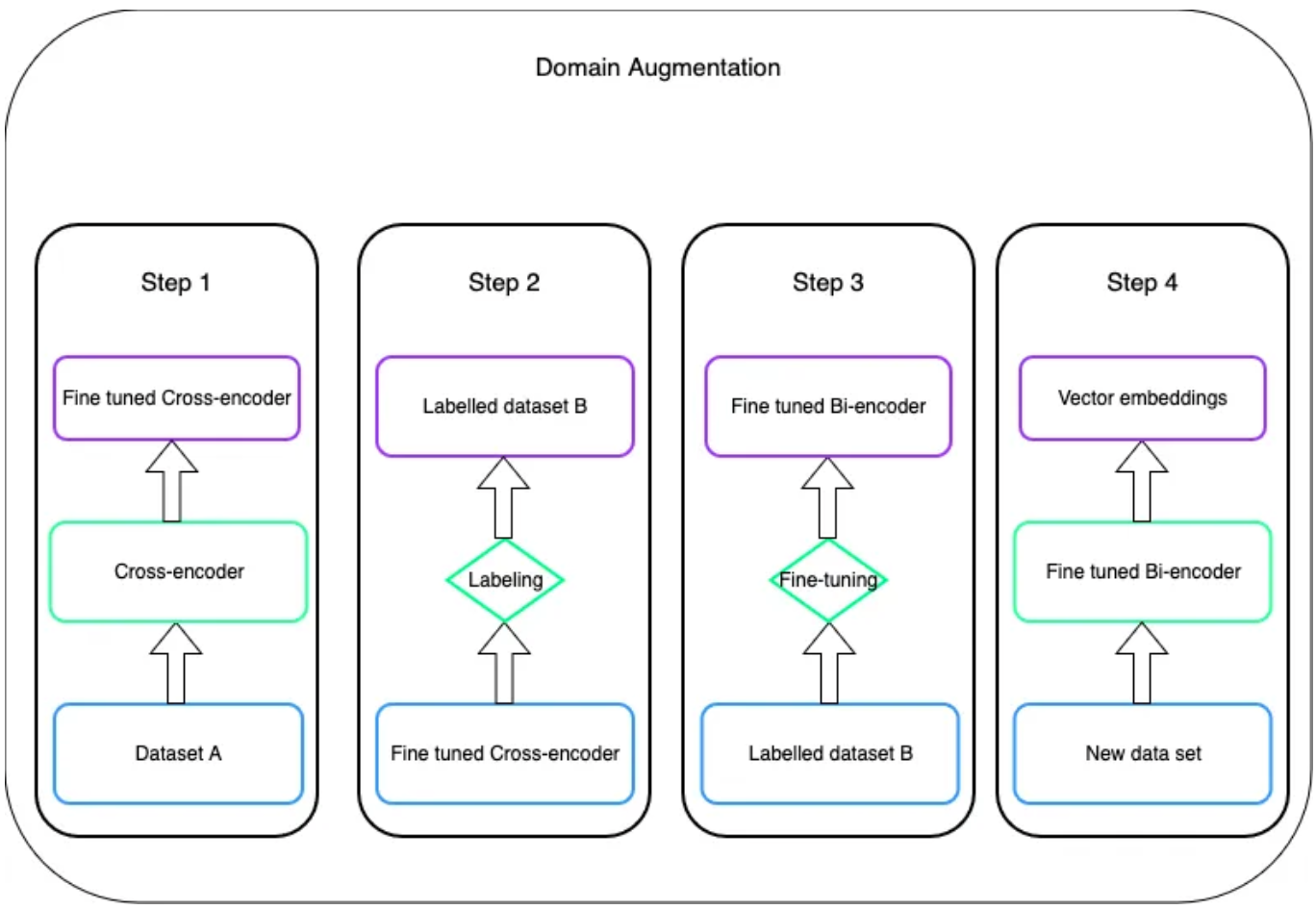
A cool trick you can use to improve retrieval performance in your RAG pipelines is fine-tune the embedding model (bi-encoder) based on labels from a cross-encoder 💡
Cross-encoders are crucial for reranking but are way too slow for retrieving over large numbers of documents. This fine-tuning technique gives you all the speed advantages of direct embedding lookup but also better performance than a non-fine tuned embedding model.
This blog post by Delaaruna shows you how to perform this domain augmentation process and plug it into a LLamaIndex.
pipeline:
- Fine-tune the cross-encoder based on a golden dataset
- Use cross-encoder to label data
- Fine-tune embedding model on those labels
- Use fine-tuned embedding model for indexing/retrieval
RAGs and LLamaIndex
With LlamaIndex, it’s possible to create a Retrieval-Augmented Generation (RAG) system. LlamaIndex offers multiple embedding and reranking options. This article will begin by explaining how embeddings and reranking function. Following that, we’ll demonstrate how to train an embedding system using your own data. For an introduction to LlamaIndex, you can find relevant information in another article.
Read related articles: