The Web LLM team observed significant advancements in generative AI and LLM. Due to open-source initiatives such as LLaMA, Alpaca, Vicuna, and Dolly, there’s a budding prospect of constructing open-source language models and individual AI assistants.
Usually, these models demand considerable computational power. For establishing a chat feature, a substantial cluster would be mandatory to execute an inference server. Meanwhile, clients would forward their requests to these servers and fetch the inferred results. Typically, they would operate on specific GPUs that are compatible with prevalent deep-learning platforms.
The team’s initiative aims to diversify the existing environment. The primary question they posed was: is it feasible to embed LLMs directly on the client-side, allowing them to function within a browser? Achieving this could pave the way for AI models on the client-side, promising cost savings, advanced personalization, and heightened privacy. Considering the increasing prowess of the client-side, this would be a pivotal move.
Imagine the convenience if one could merely launch a browser and access AI natively within a tab. The ecosystem seems prepared for this transition. Their project confirms the viability of this idea.
Guidelines
WebGPU has recently been incorporated into Chrome. For those interested, they can explore it on Chrome 113. Versions of Chrome ≤ 112 are incompatible. Users of these versions may encounter errors like
“Find an error initializing the WebGPU device OperationError: Required limit (1073741824) is greater than the supported limit (268435456) – While validating maxBufferSize – While validating required limits.”
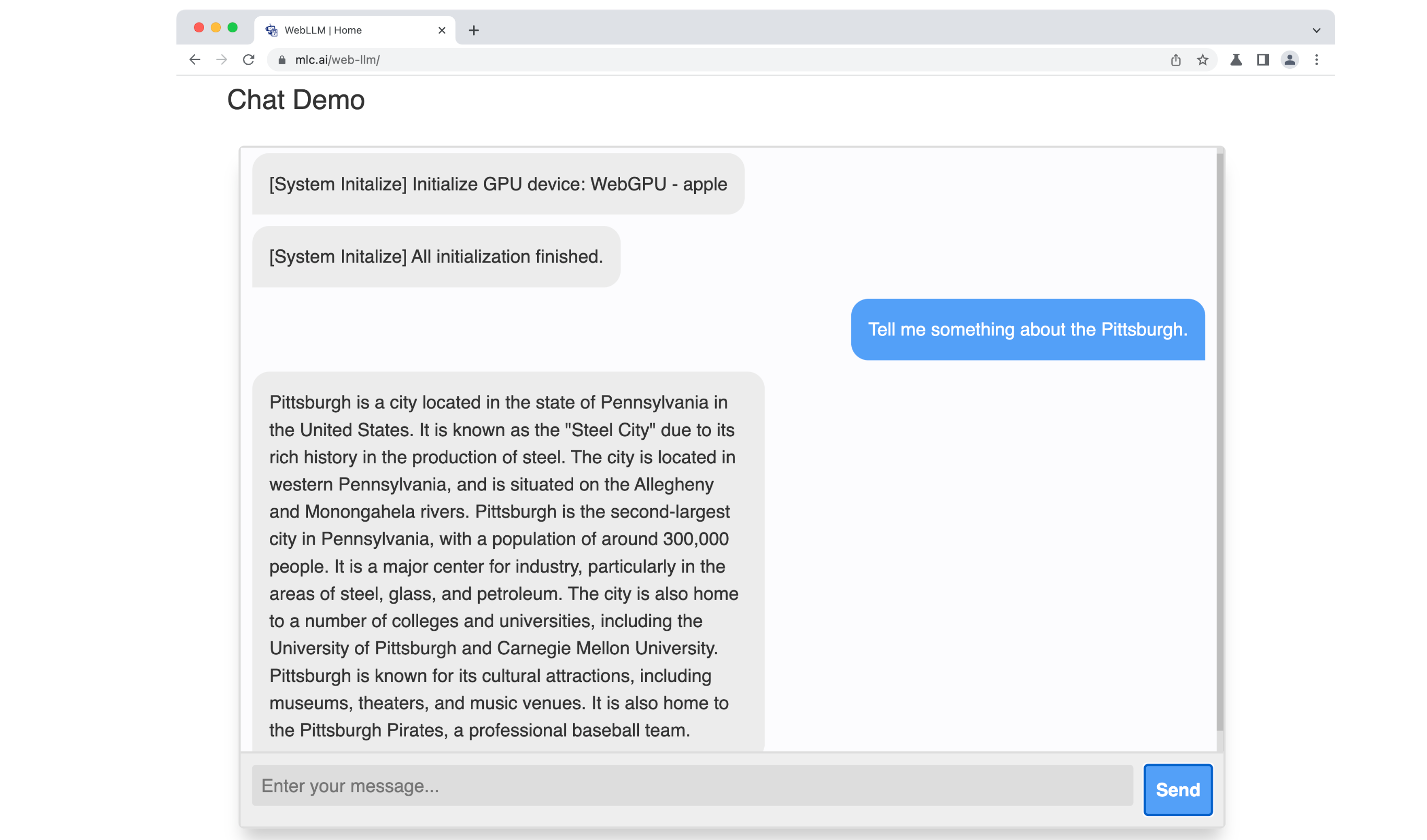
Participants can choose the model of their liking, provide their inputs, and proceed with “Send”. Initially, the chatbot will retrieve model parameters into the local cache. The initial download may take a while, but subsequent operations will be swifter. The team confirmed its functionality on both Windows and Mac. A GPU with roughly 6GB memory is necessary for Llama-7B and Vicuna-7B, while about 3GB is needed for RedPajama-3B.
Certain models necessitate fp16 support. To activate fp16 shaders, users should follow the below steps to enable it in Chrome Canary:
- Download Chrome Canary, which is Chrome’s nightly build designed for developers.
- Initiate Chrome Canary via terminal utilizing the mentioned command:
/Applications/Google\ Chrome\ Canary.app/Contents/MacOS/Google\ Chrome\ Canary --enable-dawn-features=allow_unsafe_apis
You can try online demo at: https://webllm.mlc.ai
Links
- Web LLM GitHub
- You might also be interested in Web Stable Diffusion.