
Introducing Llama 2 70B in MLPerf Inference v4.0. In the MLPerf Inference v4.0 cycle, the working group revisited the concept of a “larger” LLM task and established a new task force for this purpose. This task force evaluated a range of potential models for inclusion, including GPT-175B, Falcon-40B, Falcon-180B, BLOOMZ, and Llama 2 70B.
After thorough examination and discussion, Llama 2 70B was selected as the most appropriate model to meet the benchmarks’ objectives. It become the flagship “larger” LLM for several reasons:
- Licensing considerations: For a benchmarking consortium open to all, it is crucial that the models’ licenses are lenient. The fact allowing unrestricted access and usage not just for the participants but ideally for the press and public too. Typically, this narrows down the options to models and datasets under licenses like Apache 2.0, MIT, or similar. Llama 2’s availability through Meta’s support to MLCommons members for benchmarking activities underscores this model’s alignment with such open license requirements.
- Technical usability and deployment: Llama 2 70B is notably user-friendly and simpler to deploy than alternatives like GPT-175B. GPT require significant resources and technical effort for pre-training and tuning. The Llama-2-70B-Chat-HF model, in particular, has simplified the MLPerf benchmark development. It enabling the inclusion of a sophisticated LLM without the need for extensive resource commitment.
- Community interest: The decision also factored in the engagement and preferences of the broader ML/AI developer community, which significantly influences adoption trends across various applications. Llama 2 70B emerged as a frontrunner, leveraging metrics like engagement and leadership on platforms such as Hugging Face.
- Performance and quality: The evaluation of models took into account their accuracy and the quality of their generated text across various standard datasets designed for language modeling tasks. Llama 2 70B stood out as one of the top performers based on these metrics.
Choosing a task and a dataset for the LLM
The task force conducted a thorough examination of various popular tasks for LLMs and ultimately selected Q&A scenario for its benchmarking process. This decision was made because Q&A is one of the primary ways LLMs are currently deployed in real-world applications, offering a direct measure of a model’s ability to understand and interact using natural language. While interactive chat-based tasks, which build context through a series of exchanges, were considered, their complex evaluation requirements and the challenge of accurately measuring performance within ongoing dialogues led the task force to prefer the Q&A model. The Q&A task, with its discrete question-answer pairs, was chosen for its relevance to actual service scenarios, ease of evaluation, and clear performance metrics.
For the dataset, the task force chose the Open Orca dataset from among several highly regarded options, including datasets like AllenAI/soda. Open Orca stands out due to its comprehensive quality, being one of the largest and most diverse datasets available for question-answering tasks. It combines augmented data from the FLAN Collection with a million GPT-4 completions, providing a rich foundation for assessing the natural language processing (NLP) capabilities of LLMs.
To make the benchmarking process more efficient, the task force decided to utilize a subset of 24,576 samples from the Open Orca dataset. This subset was carefully curated based on criteria such as the quality of prompts, the origin of samples (e.g., cot, flan), and specific limits on input and output lengths (up to 1,024 tokens each), with a minimum length for reference responses set at three tokens. This curated validation set aims to ensure a meaningful and efficient evaluation. Further details on the selection and curation process can be found in the processorca.py documentation.
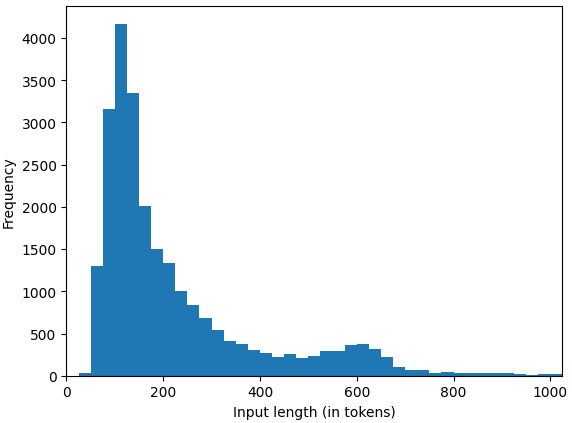
The observations from the dataset analysis indicate that, on average, the Llama 2 70B model tends to produce longer outputs compared to GPT-4. Additionally, it was noted that certain output sequences generated by our model exceed the set limitation of 1,024 tokens, failing to conclude their generation within this predefined token boundary.
Choosing accuracy metrics for the LLM
To ensure a thorough and high-quality evaluation of Large Language Models (LLMs), the LLM inference task force meticulously considered the selection of appropriate accuracy metrics, balancing the potential trade-offs between accuracy and performance during optimization. The task force underscored the importance of submissions aligning closely with the outputs of a 32-bit floating-point (FP32) reference model, which serves as a benchmark for canonical correctness.
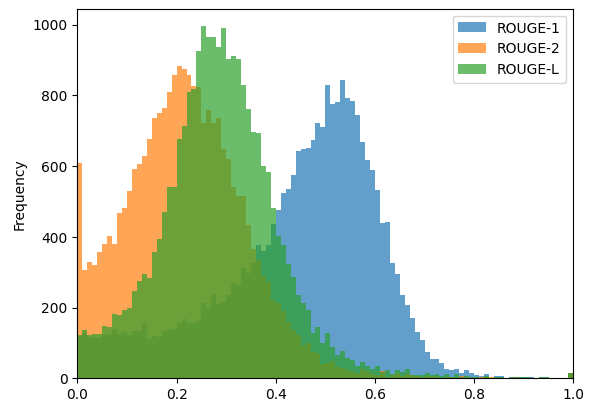
In exploring various accuracy metrics suitable for language models, such as perplexity, MMLU, MAUVE, and ExactMatch, the task force noted that some metrics might not fully account for the entirety of the generated text, while others could exhibit non-deterministic behavior. Ultimately, the task force decided on utilizing ROUGE scores as the primary accuracy metrics. ROUGE scores, which are n-gram-based metrics, are particularly adept at evaluating how closely generated text matches a reference, thus serving as an effective measure of textual similarity.
The decision was made to adopt a trio of ROUGE metrics for the benchmark: ROUGE-1, ROUGE-2, and ROUGE-L, which collectively provide a comprehensive assessment of the models’ output quality:
- ROUGE-1 = 44.4312
- ROUGE-2 = 22.0352
- ROUGE-L = 28.6162
For the Llama 2 70B benchmark, submissions were classified into two categories based on their accuracy scores: the first category required scores to exceed 99.9% of the reference ROUGE scores, while the second category required scores to surpass 99% of the reference scores. However, due to the absence of v4.0 submissions with accuracy below 99.9%, the results table for this iteration only features submissions from the highest accuracy category.
To further refine the benchmarking criteria, the task force introduced a generation length guideline of 294.45 tokens per sample, allowing a tolerance range of +/- 10%. This additional specification aims to standardize the length of generated outputs, ensuring a consistent basis for comparison across submissions.
Measuring performance of the LLama-2 70B LLM
LLM performance measures how models process and generate language from inputs, from tokens to paragraphs. Benchmarking focuses on tasks like completing texts. It involves two steps: the prompt/context phase and the subsequent generation phase. In the generation phase, each new token is produced one at a time, leveraging the context established by previous computations.
Given the nature of LLM operations, traditional throughput metrics like queries per second are not entirely suitable due to the significant variance in the computational workload across different LLM inferences. This variation stems from the differing lengths of input and output tokens for each query. Hence, the task force has opted for a metric of tokens per second for measuring throughput. This choice is in line with industry standards for LLM throughput measurement, offering a clear and universally understood metric that accurately reflects the computational effort and speed of an LLM inference across both the prompt and generation phases.v
Read related articles: