
Meta has announced a major advancement in AI technology by releasing its first lightweight quantized Llama models. These models, small and efficient enough to run on many popular mobile devices, represent a breakthrough in the field of artificial intelligence (AI), particularly in terms of accessibility and performance.
What Makes Quantized Llama Models Stand Out?
Meta’s new Llama models are not just smaller versions of existing models—they are carefully optimized to retain performance while significantly reducing their computational demands. The company, leveraging its access to vast compute resources, high-quality training data, and robust safety evaluations, has developed these models to meet both technical and ethical benchmarks.
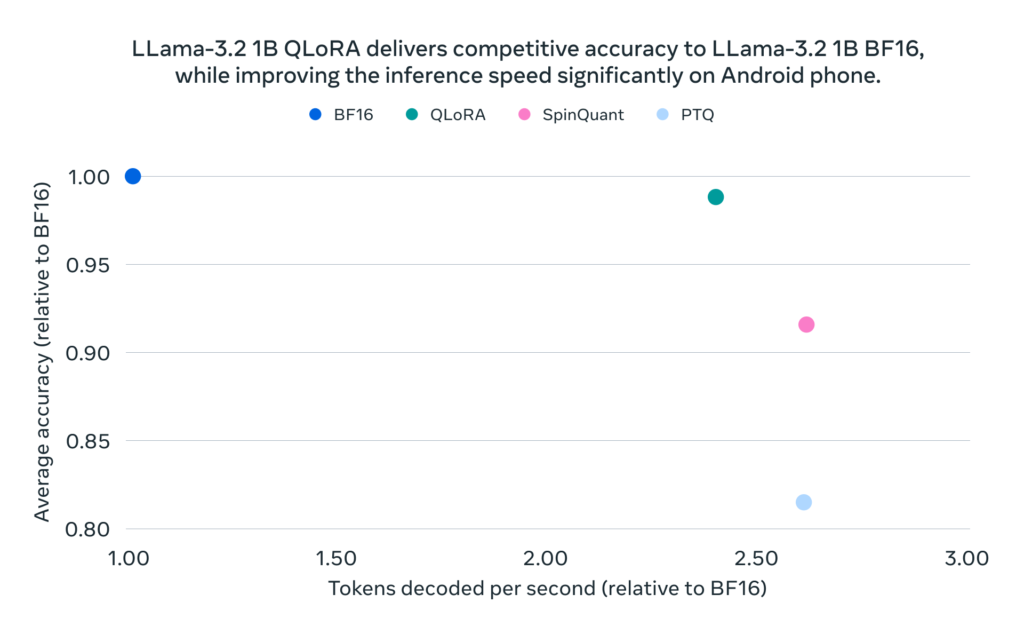
while improving the inference speed significantly on Android phone.
The models are based on Llama 3.2 and come in 1B and 3B parameter variants. They’re designed to achieve a 2-4x speedup in inference time compared to their original versions. This increased speed doesn’t come at the cost of performance; in fact, Meta reports an average reduction of 56% in model size and a 41% reduction in memory usage compared to the original BF16 (brain floating-point 16-bit) format. This means that the models are not only faster but also require significantly less hardware to run, making them much more mobile-friendly.
How Did Meta Achieve This?
Meta utilized two key techniques to quantize the Llama 1B and 3B models:
- Quantization-Aware Training (QAT) with LoRA adaptors: This technique ensures that the models maintain high accuracy while being quantized. QAT allows the model to “learn” how to be efficient during the training process itself, minimizing any potential accuracy loss.
- SpinQuant: A state-of-the-art post-training quantization method that focuses on portability, SpinQuant helps ensure the models can run smoothly on a wide range of devices, particularly mobile devices using Qualcomm and MediaTek Systems-on-Chips (SoCs) with Arm CPUs.
These techniques allow Meta to offer efficient, highly portable models that can maintain performance even in resource-constrained environments like smartphones and tablets.
Integration with Llama Stack and PyTorch
The quantized Llama models are supported by PyTorch’s ExecuTorch framework, allowing developers to run inferences using both quantization techniques. ExecuTorch is a high-performance inference execution engine within PyTorch, optimized for efficient AI computation on various devices. This integration makes it easier for developers to take full advantage of these models, both in research and in real-world applications.
Collaborating with Industry Leaders
Meta didn’t build these models in isolation. The company worked closely with industry-leading partners to ensure optimal performance on popular mobile SoCs, particularly those by Qualcomm and MediaTek. These collaborations enable seamless integration of the models with mobile hardware, making high-performance AI applications more widely available than ever before.
The Future of AI on Mobile Devices
The release of these quantized Llama models represents a significant step toward making powerful AI more accessible on mobile platforms. With the rise of AI-powered applications, from voice assistants to real-time translation tools, having lightweight yet performant models is crucial for delivering a smooth user experience without the need for extensive cloud-based resources.
By optimizing both the speed and size of these models, Meta has opened the door for more complex AI tasks to be executed directly on mobile devices, reducing latency and improving overall user interactions. This development also offers exciting opportunities for developers, who can now deploy sophisticated AI applications across a broader range of devices without sacrificing performance.
Conclusion
Meta’s release of lightweight quantized Llama models is a game-changer for mobile AI. Through innovative quantization techniques, these models strike a balance between performance and efficiency, making them ideal for deployment on everyday devices. By partnering with industry leaders like Qualcomm and MediaTek, Meta is ensuring that powerful AI is within reach for a much wider audience. As AI continues to shape the future of technology, this move brings us one step closer to truly ubiquitous intelligent applications.
Read other articles in our Blog: