Finally, we have a hallucination leaderboard! Key Takeaways:
- Not surprisingly, GPT-4 is the lowest.
- Open source LLama 2 70B is pretty competitive!
- Google’s models are the lowest. Again, this is not surprising given that the #1 reason Bard is not usable is its high hallucination rate.
Really cool that we are beginning to do these evaluations and capture them in leaderboards!
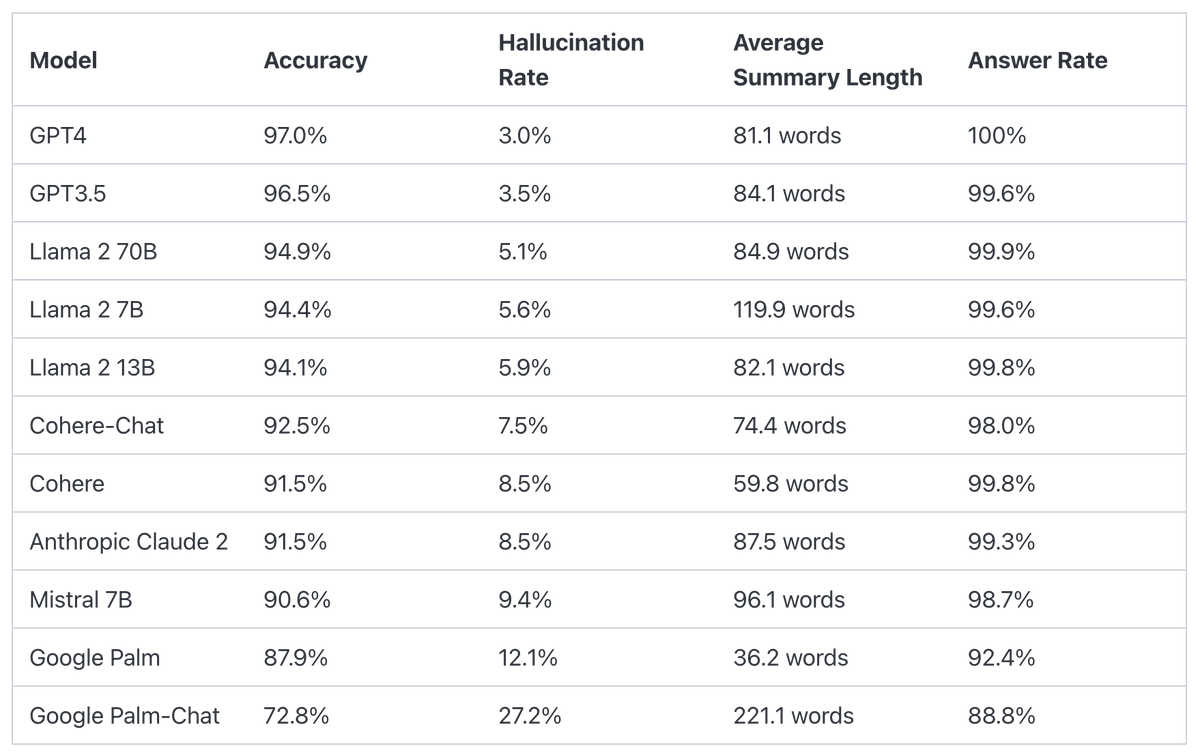
Hallucination Comparison Table
The leaderboard for publicly available language models has been determined through the use of Vectara’s Hallucination Evaluation Model. This tool assesses the frequency with which a language model generates hallucinations during the summarization of a document. It is our intention to frequently refresh this leaderboard to reflect updates to both our evaluation model and the language models themselves.
The information was most recently refreshed on November 1st, 2023.
| Model | Accuracy | Hallucination Rate | Answer Rate | Average Summary Length (Words) |
|---|---|---|---|---|
| GPT 4 | 97.0 % | 3.0 % | 100.0 % | 81.1 |
| GPT 4 Turbo | 97.0 % | 3.0 % | 100.0 % | 94.3 |
| GPT 3.5 Turbo | 96.5 % | 3.5 % | 99.6 % | 84.1 |
| Llama 2 70B | 94.9 % | 5.1 % | 99.9 % | 84.9 |
| Llama 2 7B | 94.4 % | 5.6 % | 99.6 % | 119.9 |
| Llama 2 13B | 94.1 % | 5.9 % | 99.8 % | 82.1 |
| Cohere-Chat | 92.5 % | 7.5 % | 98.0 % | 74.4 |
| Cohere | 91.5 % | 8.5 % | 99.8 % | 59.8 |
| Anthropic Claude 2 | 91.5 % | 8.5 % | 99.3 % | 87.5 |
| Mistral 7B | 90.6 % | 9.4 % | 98.7 % | 96.1 |
| Google Palm | 87.9 % | 12.1 % | 92.4 % | 36.2 |
| Google Palm-Chat | 72.8 % | 27.2 % | 88.8 % | 221.1 |
The performance metrics for GPT4 Turbo appear on par with GPT4 in the provided statistics. However, this similarity arises from the exclusion of certain documents that some models decline to summarize. In a head-to-head comparison across all summaries, with both GPT4 and its Turbo variant summarizing every document, the Turbo version exhibits a slight decrease in performance, approximately 0.3% below GPT4. Nonetheless, it still outperforms the GPT 3.5 Turbo model.
The model employed to calculate the rankings on this leaderboard has been open-sourced for commercial utilization and is available on Hugging Face.
For access to the model and guidelines on how to utilize it, visit: https://huggingface.co/vectara/hallucination_evaluation_model. Here, you can find comprehensive instructions for implementing the model for hallucination evaluation purposes.
Read related articles: